Databricks Generative AI Associate Exam Study Notes

Last week, I passed the Databricks Generative AI Associate exam. Since I struggled to find good preparation resources, I decided to write this short blog post to share what helped me along the way.
I hope that this will give you enough information to flatten the learning curve and decrease the time needed for exam preparation.
The main resources I used are:
- Official Exam Guide
- Generative AI Engineering With Databricks Course - Available in Databricks Academy
- Databricks Generative AI Engineer Associate Certification: Study Guide
- Udemy Test Exams
If you have any additional questions and suggestions, please don’t hesitate to reach out.
I wish you all the best on the exam and I’m sure you’ll do great! 🥳 🎉
Exam Questions Objectives
- Apply a chunking strategy for a given document structure and model constraints
- Identify needed source documents that provide the necessary knowledge and quality for a given RAG application
- Choose the appropriate Python package to extract document content from the provided source data and format
- Select an embedding model context length based on source documents, expected queries, and optimization strategy
- Select the best LLM based on the attributes of the application to be developed
- Choose best evaluation metric based on the particular use case
- Select the appropriate LLM model for a given task - for example Q\&A or Code generation
- Depending on the customer needs - latency, accuracy, reliability etc select appropriate model configuration
- Select method of regulating final responses - think about harmful language, toxicity etc
- How to achieve certain output from an LLM - usually by providing few-shots i.e. some examples, or adding system prompts
Concepts
Context Window - The context window of LLMs is the number of tokens a model can take as input when generating responses.
LLM Guardrails - Guardrails are the set of safety controls that monitor and dictate a user’s interaction with a LLM application. They are a set of programmable, rule-based systems that sit in between users and foundational models in order to make sure the AI model is operating between defined principles in an organization. See: LlamaGuard
Aspect-Based Sentiment Analysis - ABSA is an extension of sentiment analysis that not only determines the sentiment but also identifies specific aspects or features of the product that the sentiment refers to.
Prompt Coverage - Refers to the ability of the model to understand and respond directly to a wide range of prompts. This metric is more relevant during the training and validation phase of the model than monitoring of deployed model.
Beam Search Decoder - is often used in text generation tasks to output sequences e.g. summaries, in a controlled and optimized way. It explores multiple possible output sequences and selects the most probable one, making it suitable for summarization tasks. More information.
Model Signature - Defines the expected input and output format for the model. This is crucial for deployment as it ensures that the model will receive data in the correct format and produce outputs in the expected structure. Without a properly defined model signature, there could be mismatches between the deployed model’s expectations and the data it processes.
Chain Of Though Prompting - CoT prompting enhances the reasoning capabilities of LLMs by guiding them to articulate their though processes step-by-step, similar to human reasoning.
Retrieval Augmented Generation - RAG - is a pattern that can improve the efficiency of LLM apps by leveraging custom data.
Temperature - Model temperature meaning sampling temperature. 0 is deterministic, higher values introduce more randomness.
Top P - The probability threshold user for nucleus sampling
Top K - Defines the number of K most likely tokens to use for top-k filtering. Set this value to 1 to make outputs deterministic.
Chunk Overlap - Defines the amount of overlap between consecutive chunks, ensuring that no contextual information is lost between chunks.
Window summarization - is a context-enriching chunking method where each chunk includes a “windowed summary” of the previous few chunks.
Hierarchical Navigable Small Words - HNSW - builds proximity graph based on Euclidean L2 distance
LLM-as-a-judge - is an evaluation method where you use LLMs to evaluate the outputs. It’s a scalable alternative to the human evaluation.
LangChain - a software framework designed to help create GenAI apps that utilize LLMs. Enables apps to be context-aware, reason, and interact dynamically with various data sources and environments. Includes components for building chains and agents, integrations with other tools, and off-the-shelf implementations for common tasks.
Models
DBRX
- Release date: March 27, 2024
- Developed by Databricks
- State of the art, open source, free
- Inference is up to 2x faster than LLaMA2-70B
- DBRX is a transformer-based decoder-only large language model (LLM) that was trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input. It was pretrained on 12T tokens of text and code data.
- Two flavors
- DBRX BASE - pretrained model, it functions like a smart autocomplete, useful for further fine-tuning on your data
- DBRX INSTRUCT - finetuned model, designed to answer questions and follow instructions
- Introducing DBRX: A New State-of-the-Art Open LLM
BGE
- BAAI General Embedding
- BAAI stands for Beijing Academy of Artificial Intelligence
- This model can map any text to a low-dimensional dense vector which can be used for tasks like retrieval, classification, clustering, or semantic search
MPT
- Stands for MosaicML Pretrained Transformer
- It’s a series of LLMs depending on the number of parameters and purpose
- MPT-7B, MPT-30B etc
- MPT-7B Base, MPT-7B Chat etc
- Open source, available for commercial use, and matches the quality of Llama models
- Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs
Dolly
- Developed by Databricks
- Dolly 2.0, the first open source, instruction-following LLM, fine-tuned on a human-generated instruction dataset licensed for research and commercial use.
- Dolly 2.0 is a 12B parameter language model based on the EleutherAI pythia model family and fine-tuned exclusively on a new, high-quality human generated instruction following dataset, crowdsourced among Databricks employees.
- Free Dolly: Introducing the World’s First Truly Open Instruction-Tuned LLM
Llama
- Llama2 - family of pretrained and finetuned LLMs released by Meta AI in 2023. Released free of charge for research and commercial use. Llama2 AI models are capable of a variety of NLP tasks, from text generation to programming code.
- When exam question focuses on particular use case, for example code generation
- think about specific Llama, in this case CodeLlama
- Llama3, Released April 18, 2024. This release features pretrained and instruction-fine-tuned language models with 8B and 70B parameters that can support a broad range of use cases.
- Our new 8B and 70B parameter Llama 3 models are a major leap over Llama 2 and establish a new state-of-the-art for LLM models at those scales.
MT5
- Multilingual T5 is a massively multilingual pretrained text-to-text transformer model
- Covering 101 languages
- mT5 achieves state-of-the-art performance on many cross-lingual NLP tasks
- Multilingual T5
Model Lifecycle
MLflow
MLflow - manage end-to-end ML and GenAI workflows, from development to production
Each MLflow Model is a directory containing arbitrary files and an MLmodel file - a file that can define multiple flavors.
Managing models with UC:
- Model lifecycle management with versioning and aliases
- Deploy and organize models
- Collaboration and ACLs
- Lineage
MLflow abstracts dependency and environment management, packaging model, and code using model flavor, there are multiple deployment options.
GenAI Model Deployment
Note: Edge (on-device) deployments with LLMs are challenging due to space requirements
Batch
Batch deployment is the simplest deployment strategy. Batch processing generates predictions on a regular schedule and writes the results out to persistent storage to be consumed downstream.
Ideal for cases when:
- Immediate predictions are not necessary
- Predictions can be made in batch fashion
- Number/volume of records to predict is large
Advantages
- Cheapest deployment method
- Ease of implementation
- Efficient per data point
- Can handle high volume of data
Limitations
- High latency
- Stale data
- Not suitable for dynamic or rapidly changing data
- Not suitable for streaming data or real-time apps
Batch inference from SQL using ai_query() - Invoke Foundation Models API
with automatic parsing of completions
SELECT AI_QUERY(
"databricks-dbrx-instruct",
CONCAT(
"Based on the following customer review, answer to ensure satisfaction. Review: ", review
)
) AS generated_answer FROM reviews;
Scaling batch inference is NOT frictionless
- Access to GPUs with large memory for LMs
- Parallelization is not trivial
Think about OSS integrations - TensorRT, vLLM, Ray on Spark etc.
Streaming
- Latency is much lower than batch, we are talking about 5-10 seconds window
- Micro batching
- Medium throughput
- It’s essentially a batch job where a batch size is small
- It’s not on a fly
Real-time
The process of serving ML models in a production environment where predictions are generated instantly in response to incoming data or requests.
This is crucial for apps that require low-latency responses, such as chatbots, message intent detection, autonomous systems, and other time-sensitive tasks.
With the emergence of GenAI apps, this deployment method is becoming increasingly common, especially as LLMs need to be served in real-time.
Challenges:
- Infrastructure is hard - Real-time AI systems require fast and scalable serving infrastructure, which is costly to build and maintain
- Deploying real-time models needs disparate tools
- Operating production AI requires expert resources
Databricks Model Serving:
- Production-grade Serving
- Accelerate deployments using Lakehouse-Unified Serving
- Simplified Deployment
Model Serving:
- Custom Models - deploy any model as a REST API with serverless compute, managed via MLflow
- Foundation Models APIs - Databricks curates top Foundation Models and provides them behind simple APIs
- External Models - Govern external models and APIs. This provides the governance of MLflow AI Gateway plus the monitoring and payload logging of traditional Databricks Model Serving.
- Built-in payload logging and infrastructure/system observability
RAG
Main concepts of Rag Workflow:
- Index & Embed
- Vector Store
- Retrieval
- Filtering & Reranking
- Prompt Augmentation
- Generation
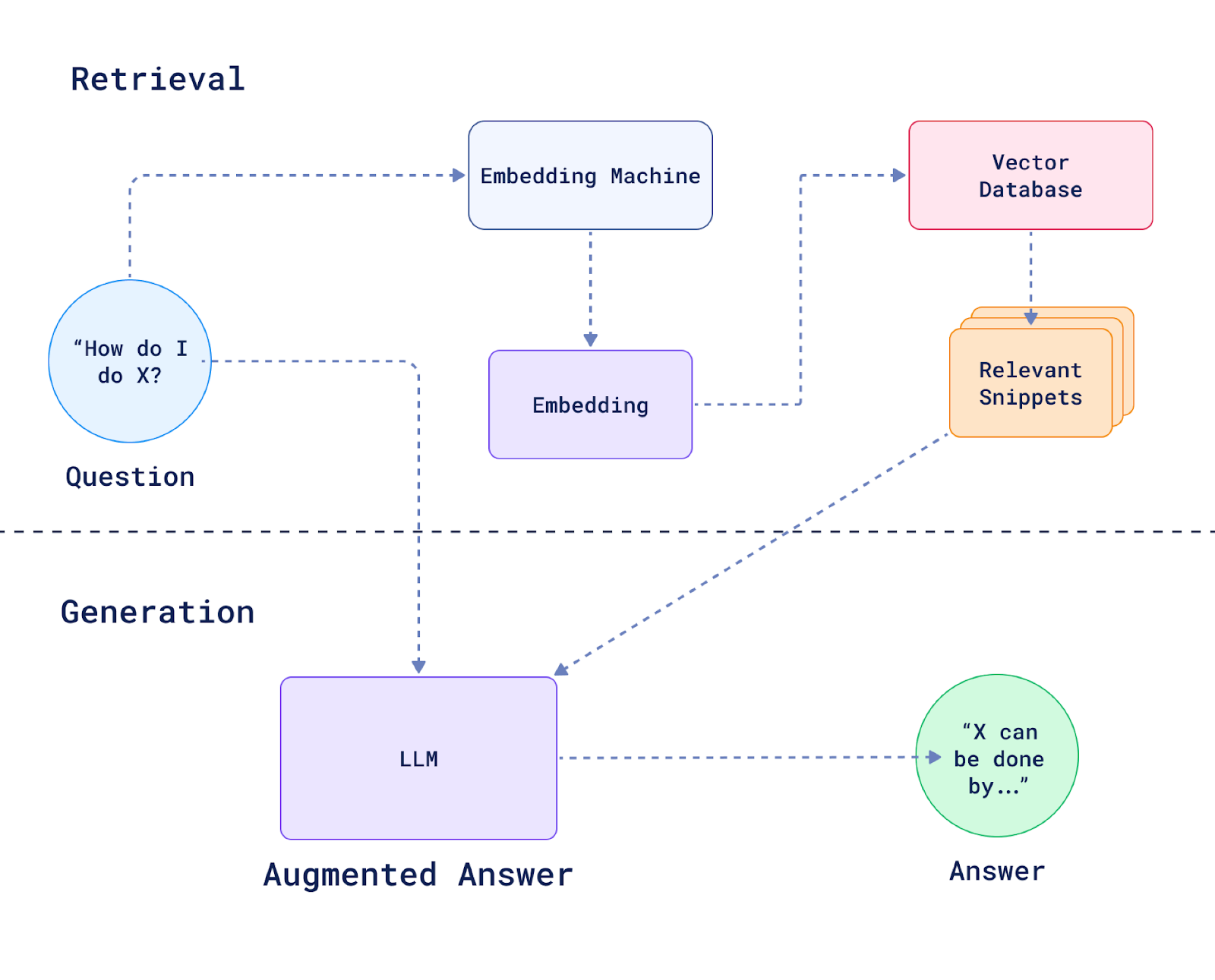
Choosing the right embedding model for your application:
- Think about specific domains and topic
- Multi-language support
- Embedding dimensions/size - more storage cost for higher dimensions
- Be aware of context window limitations. Many embedding models will ignore text beyond their context window limits
- Whatever you do - use the same embedding model for indexing and querying! (or if you have to use a different model, make sure they are trained on similar data - therefore produce the same embedding space).
Vector Similarity
- L2 Euclidean
- Manhattan L1 distance
- Cosine similarity
Vector Search strategies
- KNN - k nearest neighbor
- ANN - approximate nearest neighbor
- Trade accuracy for speed gains
- Annoy by Spotify - tree-based
- Proximity graphs - HNSW
- Faiss by Facebook - clustering
- Hashing LSH
Reranking - A method of prioritizing documents most relevant to the user’s query
- Initial Retrieval
- Not all documents are equally important
- Reranker
- Reorder documents based on the relevance scores
- The goal is to place the most relevant documents at the top of the list
- Challenges
- LLM must be called repeatedly, increasing the cost and latency of the RAG chain
- Implementing rerankers adds complexity to the RAG pipeline
Evaluating
- When evaluating RAG solutions, we need to evaluate each component separately and together
- Components to evaluate
- Chunking - method, size
- Embedding model
- Vector store - retrieval and reranker
- Generator
Evaluation Metrics
LLM
Perplexity
- Looking at the model’s confidence in the predicted word
- A sharp peak in the language model’s probability distribution reflects a low perplexity
- Low Perplexity = High Accuracy
Toxicity
- We can compute toxicity to measure the harmfulness
- It’s used to identify and flag harmful, offensive, or inappropriate language
- Low Toxicity = Low Harm
- Uses a pretrained hate speech classification model
BLUE
- Stands for Billingual Evaluation Understudy
- Is the algorithm for evaluating the quality of text which has been machine-translated from one natural language to another
- Quality is considered to be the correspondence between a machine’s output and that of a human: “the closer a machine translation is to a professional human translation, the better it is” – this is the central idea behind BLEU
- It measures the similarity between the machine-generated translation and the reference translations based on the n-grams (contiguous sequences of n words) present in both. BLEU score ranges from 0 to 1, with a higher score indicating a better match between the generated translation and the references. A score of 1 means a perfect match, while a score of 0 means no overlap between the generated and reference translations.
- See Wikipedia article for more information
ROUGE
- Stands for Recall-Oriented Understudy for Gisting Evaluation
- Is a widely used evaluation metric for assessing the quality of automatic summaries generated by text summarization systems. It measures the similarity between the generated summary and one or more reference summaries
- ROUGE calculates the precision and recall scores by comparing the n-gram units (such as words or sequences of words) in the generated summary with those in the reference summaries. It focuses on the recall score, which measures how much of the important information from the reference summaries is captured by the generated summary.
- There are several evaluation metrics:
- ROUGE-N: Overlap of n-grams between the system and reference summaries
- ROUGE-1 refers to the overlap of unigrams (each word) between the system and reference summaries
- ROUGE-2 refers to the overlap of bigrams between the system and reference summaries.
- ROUGE-L: Longest Common Subsequence (LCS) based statistics. Longest common subsequence problem takes into account sentence-level structure similarity naturally and identifies longest co-occurring in sequence n-grams automatically.
- ROUGE-W: Weighted LCS-based statistics that favors consecutive LCSes.
- ROUGE-S: Skip-bigram based co-occurrence statistics. Skip-bigram is any pair of words in their sentence order.
- ROUGE-SU: Skip-bigram plus unigram-based co-occurrence statistics.
- ROUGE-N: Overlap of n-grams between the system and reference summaries
- Ref: Wikipedia article
RAG
P@K
- Precision at K
- How many relevant items are present in the top-K recommendations of the system
- More information
R@K
- Recall at K
- How many of the relevant documents were retrieved from the total available relevant documents
- See Medium Article: Recall and Precision at k for Recommender Systems for more details
AP@K
- The average of P@i for i=1,…,K
MAP@K
- The mean of the AP@K for all the users
Mean Reciprocal Rank - MRR
- Measures how early the first relevant document appears in the ranked list
- While useful for evaluating performance, it doesn’t provide insights into the diversity or full ranking of documents retrieved
Discounted Cumulative Gain - DCG
- Is a metric that evaluates the relevance of retrieved documents while accounting for their position in the ranked list
- The higher the ranking of a relevant document, the more its relevance contributes to the score
- DCG can also be extended to Normalized DCG i.e. nDCG which compares the ranking to an ideal ranking
Jaccard Similarity
- Also called the Jaccard Index
- Is a statistic used to gauge the similarity and diversity of sample sets. It is defined in general as the ratio of two sizes, the intersection size divided by the union size, also called intersection over the union.
- It can be used in RAG applications as a measure of similarity between two asymmetric binary vectors or a way to find the similarity between two sets. It is a common proximity measurement used to compute the similarity of two items, such as two text documents.
Context Precision
- Retrieval related metric
- Signal-to-noise ration for the retrieved context
- Based on Query and Context
- It assess whether the chunks/nodes in the retrieval context ranked higher than irrelevant ones
Context Relevancy
- Measure the relevancy of the retrieved context
- It does not necessarily consider the factual accuracy but focuses on how well the answer addresses the posed question
Context Recall
- Measures the extent to which all relevant entities and information are retrieved and mentioned in the context provided
Faithfulness
- Generation related metric
- Measures the factual accuracy of the generated answer in relation to the provided context
Answer Relevancy
- Assess how pertinent and applicable the generated response is to the user’s initial query
Answer Correctness
- Measures the accuracy of the generated answer when compared to the ground truth
- Encompasses both semantic and factual similarity with the ground truth
Performance
Model Quantization
Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and activations with low-precision data types like 8-bit integer (int8) instead of the usual 32-bit floating point (float32).
Reducing the number of bits means the resulting model requires less memory storage, consumes less energy (in theory), and operations like matrix multiplication can be performed much faster with integer arithmetic. It also allows to run models on embedded devices, which sometimes only support integer data types.
Ref: https://huggingface.co/docs/optimum/en/concept_guides/quantization
Model Distillation
AKA Knowledge Distillation
In machine learning, knowledge distillation or model distillation is the process of transferring knowledge from a large model to a smaller one. While large models (such as very deep neural networks or ensembles of many models) have more knowledge capacity than small models, this capacity might not be fully utilized.
Model distillation involves fine-tuning smaller, cost-efficient models using outputs from more capable models, allowing them to match the performance of advanced models on specific tasks at a much lower cost.
Ref: https://en.wikipedia.org/wiki/Knowledge_distillation
Masking PII
Use Entity Masking with Static Preprocessing, which involves identifying and replacing PII in the dataset before the data is passed into the model. This method allows for high performance inference as the masking is done beforehand, ensuring the model does not need to spend resources on handling PII during inference. This method is particularly useful for high throughput scenarios, such as realtime customer feedback analysis, as it minimizes runtime overhead while maintaining privacy.
Masking with Complete Blackout i.e. replacing sensitive information with empty or null values removes too much context from the data, leading to reduced model performance, as the model cannot learn or infer from missing information.
Masking at Inference Time - introduces significant computational overhead, as the model must perform additional operations to identify PII on the fly.
Code Examples
LLM LangChain Prompt
from langchain.chains import LLMChain
from langchain_community.llms import OpenAI
from langchain_core.prompt import PromptTemplate
prompt_template = "Tell me a {adjective} joke"
prompt = PromptTemplate(
input_variable=["adjective"],
template=prompt_template
)
llm = LLMChain(llm=OpenAI(), prompt=prompt)
llm.generate([{"adjective": "funny"}])
Use Mosaic AI Vector Search as vector store
from databricks_langchain import DatabricksVectorSearch
vector_store = DatabricksVectorSearch(index_name="<YOUR_VECTOR_SEARCH_INDEX_NAME>")
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
retriever.invoke("What is Databricks?")
See Use Mosaic AI Vector Search as vector store for more information.
Use Chat Model
The following example shows how to use the Meta’s Llama 3.1 70B Instruct model as an LLM component in LangChain using the Foundation Models API.
from databricks_langchain import ChatDatabricks
chat_model = ChatDatabricks(
endpoint="databricks-meta-llama-3-1-70b-instruct"
temperature=0.1,
max_tokens=250,
)
chat_model.invoke("How to use Databricks?")
See Chat Models for more information.
Use Online Tables with Mosaic AI Model Serving
training_set = fe.create_training_set(
df=id_rt_feature_labels,
label='quality',
feature_lookups=[
FeatureLookup(
table_name="user_preferences",
lookup_key="user_id"
)
],
exclude_columns=['user_id'],
)
See section for more information.
Create a Feature Serving Endpoint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
endpoint_name = "fse-location"
workspace.serving_endpoints.create_and_wait(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name=feature_spec_name,
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
See step 2 for more information.
Helper Libraries
unstructured
unstructured- is an open-source Python library that provides components for ingesting and preprocessing images and text documents, such as PDFs, HTML, Word docs etc- This library can be useful for preprocessing stage of context building in a RAG application
- Ref: https://pypi.org/project/unstructured/
pypdf
pypdfis a free and open source pure-python PDF library capable of splitting, merging, cropping, and transforming the pages of PDF files.- It can also add custom data, viewing options, and passwords to PDF files.
- pypdf can retrieve text and metadata from PDFs as well.
- Ref: https://pypi.org/project/pypdf/
Apache Tika
- Robust tool for extracting text from various file formats
- Ref: https://tika.apache.org/
Haystack
- Is an open source Python framework for building custom apps with LLMs, focusing on document retrieval, text generation, and summarization
- End-to-end LLM framework that allows you to build applications powered by LLMs, Transformer models, vector search and more. Whether you want to perform retrieval-augmented generation (RAG), document search, question answering or answer generation, Haystack can orchestrate state-of-the-art embedding models and LLMs into pipelines to build end-to-end NLP applications and solve your use case
- Ref: https://github.com/deepset-ai/haystack
DSPy
- Framework for programming with LLMs and retrieval models - RMs. It provides a structured and composable approach to tasks involving LMs, going beyond manual prompting techniques
- Components
- Signatures - declarative modules that guide LLMs, following a Pythonic structure. Examples include ChainOfThough, Retrieve, and ReACT
- Teleprompters - optimizers that “compile” a program into instructions, few-shot prompts, or weight updates tailored for a specific LM
- Automatic Compiler - an automatic compiler that traces the execution of a program and generates high-quality prompts or automatically fine-tunes LMs to internalize the task’s procedural details
- Ref: https://github.com/stanfordnlp/dspy
Databricks
Vector DB in Databricks is Vector Search.
Databricks serving models - Custom Models, External Models, Foundational Models etc.
MLflow LangChain Flavor - the primary solution that will allow you to package the whole chain as part of a single model.
Foundation Model API - Access and query state-of-the-art open GenAI
models.
Features:
- Pay-per-token for low-throughput apps and provisioned throughput for high-throughput
- Users can integrate external models, such as Azure OpenAI GPT models or AWS Bedrock Models
- Unified interface for deploying, governing, and querying AI models
Inference Tables
- The inference table automatically captures incoming requests and outgoing responses for a model-serving endpoint and logs them as a UC Delta table
- You can use the data in this table to monitor, debug, and improve ML models
- You can enable inference tables on any existing or newly created model serving endpoint, and requests to that endpoint are then automatically logged to a table in UC
Online Tables
An online table is a read-only copy of a Delta Table that is stored in row-oriented format optimized for online access. Online tables are fully serverless tables that auto-scale throughput capacity with the request load and provide low latency and high throughput access to data of any scale.
Online tables are designed to work with Mosaic AI Model Serving, Feature Serving, and retrieval-augmented generation (RAG) applications where they are used for fast data lookups.
Databricks Lakehouse Monitoring - Automated insights and out-of-the-box metrics on data and ML pipelines
- Fully managed - so no time wasted managing infrastructure calculating metrics, or building dashboards from scratch
- Frictionless - with easy setup and out-of-the-box metrics and generated dashboards
- Unified - solution for data and models for holistic understanding
- The table has to be managed by UC, and for each table following metrics
are supported
- Profile metrics
- Drift metrics
- Supports custom metrics as SQL expressions
- Auto-generated DBSQL dashboard to visualize metrics over time
- Automatic PII detection
- Input expression and rules
- Lakehouse monitoring types:
- Time Series - used for tables that contain a time series dataset based on a timestamp column. Monitoring data quality metrics across time-based windows of the time series
- Inference Log - used for tables that contain the request log for a model. Each row is a request with columns for the timestamp, the model inputs the corresponding prediction, and optionally ground-truth labels. Monitoring compares model performance and data quality metrics across a time-based window of the request log
- Snapshot - used for all other types of tables. Monitoring calculates data quality metrics over all data in the table. The complete table is processed with every refresh.
In Databricks Feature Store you can store the following feature types commonly used in ML apps:
- Dense vectors, tensors, and embeddings as
ArrayType - Sparse vectors, tensors, and embeddings as
MapType - Text as
StringType
When published to an online store, ArrayType, and MapType features are
stored in JSON format.
Mosaic AI Agent Evaluation
Agent Evaluation helps developers evaluate the quality, cost, and latency of agentic AI applications, including RAG applications and chains. Agent Evaluation is designed to both identify quality issues and determine the root cause of those issues. The capabilities of Agent Evaluation are unified across the development, staging, and production phases of the MLOps life cycle, and all evaluation metrics and data are logged to MLflow Runs.
Agent Evaluation includes proprietary LLM judges and agent metrics to evaluate retrieval and request quality as well as overall performance metrics like latency and token cost.
See What is Mosaic AI Agent Evaluation? for more information.
Leave a comment