Personal Project - pytransflow

Introduction
In this blog post, I’m excited to introduce pytransflow, a Python library
that I created for fun in my spare time.
This project acts as a Proof of Concept, focused on improving my approach to library design and architectural thinking. I’ve worked on it on and off; the first version of this library was about six months ago. After revisiting and rewriting most parts, I’ve now wrapped it up and feel it’s largely ready, at least for showcasing. Of course, there’s plenty of room for improvement, and I invite anyone interested to join and contribute to this project.
You can find the pytransflow’s source code in my GitHub repository:
pytransflow.
I encourage you to experiment with it, propose enhancements, and contribute to its development. Your feedback and contributions are greatly appreciated!
Acknowledgment
I want to express my gratitude to Bas Van Kortenhof for sparking the idea that led to this personal project. His work had a significant impact on both my own work and the direction of my ideas in general, including this project. Working alongside Bas was a rewarding experience, and I learned a great deal from our collaboration.
I’d also like to thank my colleagues for our discussions on potential features and their practicality within the library. The interchange of ideas and feedback played a significant role in shaping the direction and functionality of the features I implemented.
Purpose
pytransflow is a simple and lightweight library for record-level processing using flows of transformations defined as YAML files.
It provides simplicity in defining and configuring flows, schema validation, managing various errors that may occur in the processing pipeline, and handling failed records. Its design allows extensive customization for different use cases, including custom transformations, error management, evaluation functions, and more.
Some of the features pytransflow provides include:
- Define processing flows using YAML files
- Use all kinds of flow configurations to fine-tune the flow
- Leverage pydantic ‘s features for data validation
- Apply transformations only if defined condition is met
- Build your own library of transformations
- Use multiple input and output datasets
- Ignore specific errors during processing
- Set conditions for output datasets
- Track failed records
- Define flow fail scenarios
- Process records in parallel
- Use flow level variables etc.
Getting Started
Simple Flow
After installing pytransflow, create the flows directory in the root of
your project, in it create a file test_flow.yaml:
Note: You can also use
.yml, both are supported.
description: Simple Flow
transformations:
- add_field:
name: new_field
value: [1, 2, 3]
Then create a python script in the root folder:
from pytransflow.core import Flow
records = [{"a": 1}]
flow = Flow("test_flow")
flow.process(records)
print(f"Result: {flow.datasets}")
print(f"Failed Records: {flow.failed_records}")
Note: Flow parameter
test_flowmatches the filename of.yaml
The output is:
Result: {'default': [{'a': 1, 'new_field': [1, 2, 3]}]}
Failed Records: []
Path Separator
Path separator defines how nested fields are defined and accessed.
The default path separator is /.
If we use the previous example, but use nested name for add_field
transformations:
- add_field:
name: b/c/d
value: [1, 2, 3]
You’ll get
Result: {'default': [{'a': 1, 'b': {'c': {'d': [1, 2, 3]}}}]}
Default path separator value can be easily changed in the global
configuration file - Please see Global Configuration,
or defined for a specific flow using path_separator configuration.
For example
path_separator: ","
transformations:
- add_field:
name: b,c,d
value: [1, 2, 3]
Give the same result as previous example
Result: {'default': [{'a': 1, 'b': {'c': {'d': [1, 2, 3]}}}]}
Conditions
Conditions can be applied on two levels:
- Transformation - All transformations can have a
conditionparameter. This condition is evaluated before the transformation is executed. If condition is met, the transformation will be applied, if condition is not met, the whole record will be skipped and included in theoutput_datasets. - Output Dataset - Transformation
output_datasetscan contain a condition. If condition is met, the record will be included in the output dataset, if not it will be skipped. This is evaluated after the transformation is applied, not before. For more information, please see Datasets - Using Conditions
The following two sections showcase how we can apply a condition on transformation level.
Simple
Let’s look at the following example:
transformations:
- add_field:
name: b
value: 1
condition: "@a == 'A'"
The character @ is used to define a record field.
Note: pytransflow also allows defining variables on a flow level, which can be used in conditions using
!:. For more information, please see Flow Variables
Here, we are setting a condition that field a in record has to have a
value equal to A. If that’s the case, the record will be processed,
otherwise the record will be skipped
records = [
{"a": "A"},
{"a": "a"},
]
flow = Flow("<filename>")
flow.process(records)
The output dataset is:
{'default': [{'a': 'A', 'b': 1}, {'a': 'a'}]}
As we can see, only the first record is processed, the second is skipped because the condition for processing is not met.
Nested
Condition expression can be extended to use nested field and evaluation functions.
For example:
transformations:
- add_field:
name: b/e/f
value: 1
condition: "int(@a/b/c) * 2 == @d/e"
Using the following input record
records = [{"a": {"b": {"c": "2"}}, "d": {"e": 4}}]
flow = Flow("<filename>")
flow.process(records)
We get the resulting dataset
{
'default': [
{
'a': {'b': {'c': '2'}},
'd': {'e': 4},
'b': {'e': {'f': 1}}
}
]
}
Since the condition is met, the field b/e/f is added, as we can see in the
resulting dataset.
pytransflow supports creating custom evaluation function, which you can use
in all condition parameters. Please see Custom-Evaluation
for more information on how to achieve that.
Datasets
Simple Case
Dataset is a collection of records and each transformation has
input_datasets and output_datasets parameters:
input_datasets- list of dataset names from which the records will be extracted for processing.output_datasets- list of dataset names, along with optional conditions, to which we will direct processed records as output.
Default behavior:
- If
input_datasetsis not specified it will default to["default"]. This name can be configured check Global Configuration - If
output_datasetsis not specified it will be the same asinput_datasets
Let’s look at an example of 3 transformations and 4 datasets:
transformations:
- add_field:
name: a
value: test
output_datasets:
- dataset-1
- prefix:
field: a
value: pre_
input_datasets:
- dataset-1
output_datasets:
- dataset-2
- postfix:
field: a
value: _post
input_datasets:
- dataset-2
output_datasets:
- dataset-3
- dataset-4
Running this flow with an empty record
records = [{}]
flow = Flow("<filename>")
flow.process(records)
Gives the following result
{'dataset-3': [{'a': 'pre_test_post'}],
'dataset-4': [{'a': 'pre_test_post'}]}
Using Conditions
Additionally, output_datasets can contain a condition, which can be
defined in two ways.
Using <dataset-name>: <condition> pattern:
- postfix:
field: a
value: b
output_datasets:
- dataset: "@a == 2"
Or name, condition dictionary:
- postfix:
field: a
value: b
output_datasets:
- name: dataset
condition: "@a == 2"
Extending the previous example by adding condition to the last dataset:
transformations:
- add_field:
name: a
value: test
output_datasets:
- dataset-1
- prefix:
field: a
value: pre_
input_datasets:
- dataset-1
output_datasets:
- dataset-2
- postfix:
field: a
value: _post
input_datasets:
- dataset-2
output_datasets:
- dataset-3
- dataset-4: "@b == '1'"
Since there is no field b in the record, this condition will fail and
final dataset includes only dataset-3.
{'dataset-3': [{'a': 'pre_test_post'}]}
Failed Records
If some error happens during the processing, the flow won’t immediately fail.
Note: This can be changed by setting
instant_fail: True. For more information see: Instant Fail
The records that failed during processing are stored in the failed records
dataset, which can be accessed on a Flow instance after processing.
from pytransflow.core import Flow
records = [{"a": 1}]
flow = Flow("test_flow")
flow.process(records)
print(f"Failed Records: {flow.failed_records}")
Failed record contains information about the initial record, the failed record, transformation that failed, and the error that was raised.
Note: There is a difference between initial record and failed record, for more information please see How It Works
This is especially useful for debugging but also for redirecting failed records during actual processing.
If the error is ignored using ignore_errors, the record won’t end up as a
failed record, even thought the error occurred. Ignore errors configuration is
primarily used to handle errors that are expected and can be safely ignored,
these errors won’t impact the processing, since the record will remain
unprocessed and redirected to output datasets.
Ignore Errors
Ignore errors configuration is a way to handle errors that are expected and
can be safely ignored. These errors won’t impact the processing i.e. the flow
won’t fail. The ignore_errors is set on a transformation level, if the
transformation encounters the ignored error during the processing, the result
will be
- Initial record - No processing will occur and transformation just returns initial record
- Processed record - Error is ignored, but the record is processed either way.
For example, if transformation wants to store a value in field
xbut that field already exists it will raiseOutputFieldAlreadyExistsexception. However, if it’s ignored, the output field will be overwritten and the end result is a processed record, not the initial record.
Let’s illustrate that using the following examples.
Output Already Exists
transformations:
- add_field:
name: class
value: 1
If we have an initial record {"class": "a"}, this flow will result in
Result: {}
Failed Records: [
{
...,
error=OutputAlreadyExistsException(Output field 'class' already exists))],
'record': {'class': 'a'},
...
}
]
However, when we add ignore_errors for OutputAlreadyExistsException
transformations:
- add_field:
name: class
value: 1
ignore_errors:
- output_already_exists
we get
Result: {'default': [{'class': 1}]}
Failed Records: []
Output Dataset
The next example showcases that ignoring an error returns initial record that’s redirected to an output dataset for further processing.
transformations:
- add_field:
name: class
value: 1
output_datasets:
- added
ignore_errors:
- output_already_exists
- prefix:
field: class
value: pre_
ignore_errors:
- field_wrong_type
input_datasets:
- added
output_datasets:
- prefix
As in previous example, we are ignoring output_already_exists and overwriting
the field, this transformed record is then routed to added dataset, which is
used for prefix transformation. Since the record will be {"class": 1} i.e.
it’s value is int the prefix should fail but we are ignoring
field_wrong_type, and the end result is
Result: {'prefix': [{'class': 1}]}
Failed Records: []
Notice that the end result dataset is prefix, which is the output of prefix.
Schema Validation
pytransflow allows users to validate a record schema by utilizing validate
transformation which takes one argument, schema_name.
transformations:
- add_field:
name: a
value: b
- validate:
schema_name: test.TestSchema
The input format for schema_name is
<name_of_the_file>.<name_of_the_schema_class>.
The file is stored under SCHEMA_PATH which can be defined in pyproject.toml
or .pytransflowrc, but defaults to <project root>/schemas.
For more information about configuring
SCHEMA_PATH, please see Global Configuration
Schema must inherit from pydantic’s BaseModel. This allows user to leverage
all advanced features that pydantic offers, and can be highly customizable
to suit any particular needs.
Schema is imposed on a record, meaning, unnecessary fields will be removed, field types will be cast, and schema validated.
Example of a schema
# test.py
from pydantic import BaseModel
from typing import Optional
class TestSchema(BaseModel):
"""Example schema"""
first_name: str
last_name: str
middle_name: Optional[str]
birth_year: Optional[int]
...
Since the filename is test.py, and class TestSchema, we will use it as
test.TestSchema in validate transformation.
Flow Configuration
pytransflow allows flow level configuration, these parameters will influence how the flow is executed and how the flow handles different fail scenarios.
The following sections showcase available flow configuration.
Instant Fail
Parameter instant_fail is optional, defaults to False. If set to True,
the flow will throw pytransflow.exceptions.flow.FlowInstantFailException
exception if any failure is noticed in the pipeline during the processing.
Essentially, it won’t allow failed records.
For example, the following flow is using the instant_fail: False
transformations:
- add_field:
name: a
value: 1
If this flow is executed with input records = [{"b": "1"}, {"a": "2"}]. We
get the following resulting dataset
Result: {'default': [{'a': 1}]}
Failed Records: [{'failed_records': [FailedRecord(record={'a': '2'}, ...)], ...}]
Record {"a": 1} failed because the transformation add_field is trying to
add a field that already exists. However, that didn’t stop the flow from moving
to the next record and storing the failed one in failed_records.
On the other hand, if we instant_fail: True
instant_fail: True
transformations:
- add_field:
name: a
value: 1
And run it again, we will get the following traceback
...
pytransflow.exceptions.flow.FlowPipelineInstantFailException: Flow Pipeline
raised the instant fail in the flow caused by the error:
OutputAlreadyExistsException(Output field 'a' already exists)
The above exception was the direct cause of the following exception:
...
pytransflow.exceptions.flow.FlowInstantFailException: Flow raised instant fail exception
Fail Scenarios
pytransflow keeps flow statistics during the execution of a flow. Fail scenarios define cases when we want to intentionally fail a flow based on some metric.
The following sections describe some fail scenarios.
Percentage of Failed Records
fail_scenarios:
percentage_of_failed_records: 50
transformations:
- add_field:
name: a
value: 1
This example defines a threshold of 50 percent for failed records. If the
actual percentage is greater or equal to this value, the flow will fail by
raising FlowFailScenarioException exception.
For example, using the above flow and the following records:
records = [{"b": "1"}, {"a": "2"}, {"a": 3}]
Will raise the following exception:
pytransflow.exceptions.flow.FlowFailScenarioException:
Flow Fail Scenario 'percentage_of_failed_records': Threshold defined as 50, got 67
As expected, 2 of 3 records fail which results in surpassing the threshold.
Number of Failed Records
Same as the previous example, but instead of percentage we are defining the rule for number of failed records.
fail_scenarios:
number_of_failed_records: 2
transformations:
- add_field:
name: a
value: 1
In this example, if the number of failed records is equal or greater than 2,
the flow will fail, raising the FlowFailScenarioException exception.
Running this flow using the following records
records = [{"b": "1"}, {"a": "2"}, {"a": 3}]
will raise the following exception
pytransflow.exceptions.flow.FlowFailScenarioException: Flow Fail Scenario
'number_of_failed_records': Threshold defined as 2, got 2
Datasets Present
This flow failure scenario is checking if a dataset is present in the final dataset result. If it’s present, it will raise the error. The configuration parameter takes a list of strings, which represent dataset names.
fail_scenarios:
datasets_present: ["a"]
transformations:
- add_field:
name: a
value: 1
output_datasets: ["a"]
Running this flow with an empty record will raise the following exception
pytransflow.exceptions.flow.FlowFailScenarioException: Flow Fail Scenario
'datasets_present': Dataset 'a' is present
Datasets Not Present
fail_scenarios:
datasets_not_present: ["a"]
transformations:
- add_field:
name: a
value: 1
Running this flow with an empty record will raise the following exception
pytransflow.exceptions.flow.FlowFailScenarioException: Flow Fail Scenario
'datasets_not_present': Dataset 'a' is not present
Parallelization
pytransflow supports running flows in multiprocessing mode i.e. in parallel. This is achieved by creating multiple processes where each process is running a single flow pipeline and works on a batch of records. For more information on how it works, please see How it Works.
Enabling parallelization is done via parallel parameter, which
defaults to False.
parallel: True
transformations:
- add_field:
name: a
value: 1
Additional options include:
batch- Batch size i.e. number of records in a batch. If not specified, size of a batch will be equal to number of input records divided by number of available cores.cores- Number of cores, if not specified it will take the number of available cores in the system.
For example:
parallel: True
batch: 20
cores: 4
transformations:
- add_field:
name: a
value: 1
Flow Variables
Defining variables on a flow level is supported. These variables can be
used in any transformation, particularly in condition expressions. The idea
is to define a value at the beginning of the flow and just reference it
where you need it, using !: pattern.
variables:
d: "A"
transformations:
- add_field:
name: b
value: 1
condition: "@a == !:d"
Running this flow with the following input records:
records = [{"a": "A"}]
Outputs
Result: {'default': [{'a': 'A', 'b': 1}]}
However, changing it to {"a": "<something-else>"}, gives
Result: {'default': [{'a': 'a'}]}
In other words, condition for transforming the record is not met.
Note: Flow variables can be created, deleted, or modified from a transformation, if you ever wish to do so. This allows you to dynamically set flow variables. To do so, you’ll have to create a custom transformation, since this is not done in built-in transformations. Please see Custom Transformations and Flow Variables for more details.
How It Works
Overview
pytransflow is a simple library for record-level processing using flows of transformations defined as YAML files.
This section describes the bigger picture and how things are connected within pytransflow. For hands on and some examples, please see Getting Started
pytransflow has the following main components
Flow- Main object that is responsible for initiating everything that is required for record processing. Initiating aFlowis an entry point to using pytransflow. Methodprocessstarts the processing of input records. Conceptually,Flowis a collection ofTransformationobjects, but it also covers high level concepts such areFlowVariable,FlowPipeline,FlowFailScenarioetc.Transformation- Contains logic for processing a record. It can act on a single field, multiple fields, nested fields, interact with external services, transform fields in-place or output them to different fields. Transformations are executed sequentially within aFlowPipeline, more on that later.Record- Record is an object that stores key-value pairs, like dictionary. It’s the main unit of data storage and is used to carry data throughFlowPipelinewhile transformations act on it. There is also a concept ofFailedRecord, which stores information about theRecordthat failed to be processed, transformation that failed, and error messageAnalyzer- Before a transformation is executed on aRecord, we perform some checks and analysis if transformation can be applied. This includes confirming that the transformation requirements are satisfied i.e. required fields are present in the record, transformation condition expression is satisfied, output fields are not present or can be overwritten etc.Controller- Interacts withAnalyzerandTransformation. It handles when something fails during the processing of a record and returns aFailedRecord.
The following diagram depicts a simple overview of pytransflow structure
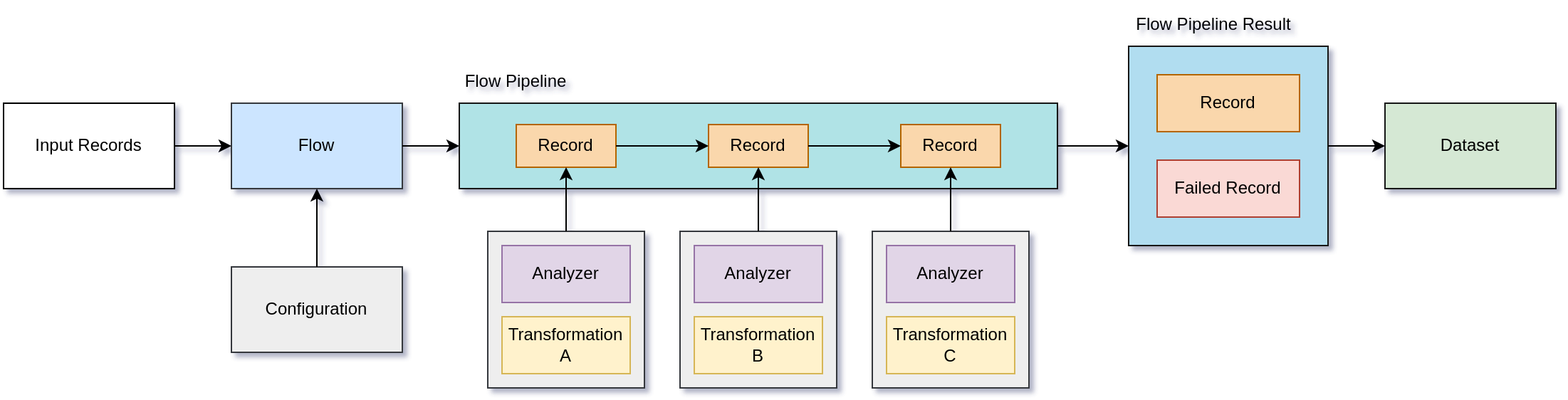
The flow configuration is defined in a YAML file, and it has the following structure
flow_param_1: a
flow_param_2: b
...
transformations:
transformation_1:
param_1: a
param_2: b
transformation_2:
param_1: c
param_2: d
...
Loading of these YAML files can be illustrated in the following fashion
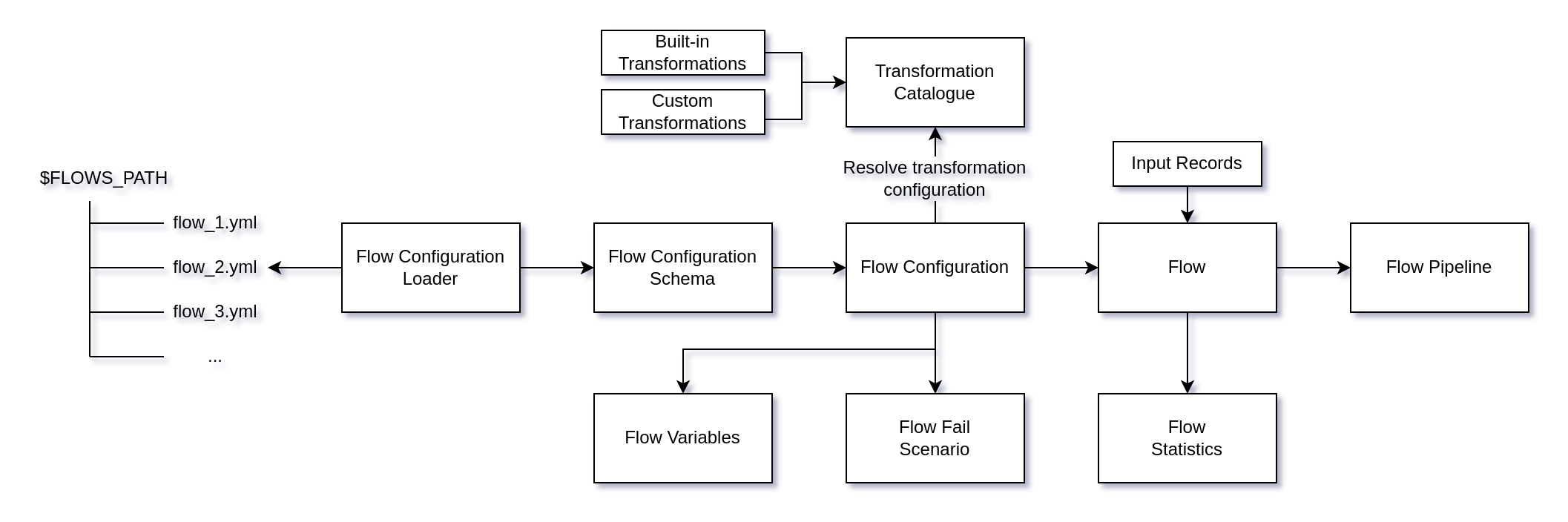
Looking at the diagram, we can see multiple concepts related to flow configuration
FlowConfigurationLoader- Finds and parses the flow configuration YAML fileFlowConfigurationSchema- Configuration schema that is validated before setting Flow configurationFlowConfiguration- Main class that holds configuration for a flow. During its initialization, it also resolves transformation configuration usingTransformationCatalogue.TransformationCatalogue- Holds mappings of transformation names to its Transformation configuration schema and transformation implementationFlowVariables- Variables that are defined on a flow level and can be used through the flowFlowFailScenario- Scenario when we want to fail a flow, for example, number of failed records is greater than some thresholdFlowStatistics- Holds information about what happened during the processingFlowPipeline- Implements a concept of a pipeline. Input records are submitted to the pipeline, one by one andFlowPipelineResultis returned. Pipelines can act differently depending on how the flow is configured. Transformations are applied to a record and in case something fails, pipeline will return aFailedRecord, ifinstant_failis enabled the whole flow will fail.
Transformation
Conditions
All transformations have condition parameter allowing execution of
transformations only if the condition is met. If condition is not met, the
unprocessed record will be routed to output datasets.
transformations:
- transformation:
...
condition: @a/b/c == 'B'
Here we are testing if {"a": {"b": {"c": "B", ...}, ...}, ...} is true.
Conditional expression can use record fields, prefixed by @, and flow
variables, prefixed by !:, see
Flow Variables.
Evaluation of condition expressions is done using
simpleeval library. It can be
extended with custom function using SimpleEval provided in
pytransflow, for more information please see
Custom Evaluation.
These conditions can be also applied for output datasets, if condition is met, record will be routed.
Input/Output Datasets
Transformations get records from one or multiple input datasets, likewise the processed records will be routed to one or multiple output datasets.
transformations:
- transformation:
...
input_datasets:
- a
- b
output_datasets:
- c
- d
This configuration looks like this
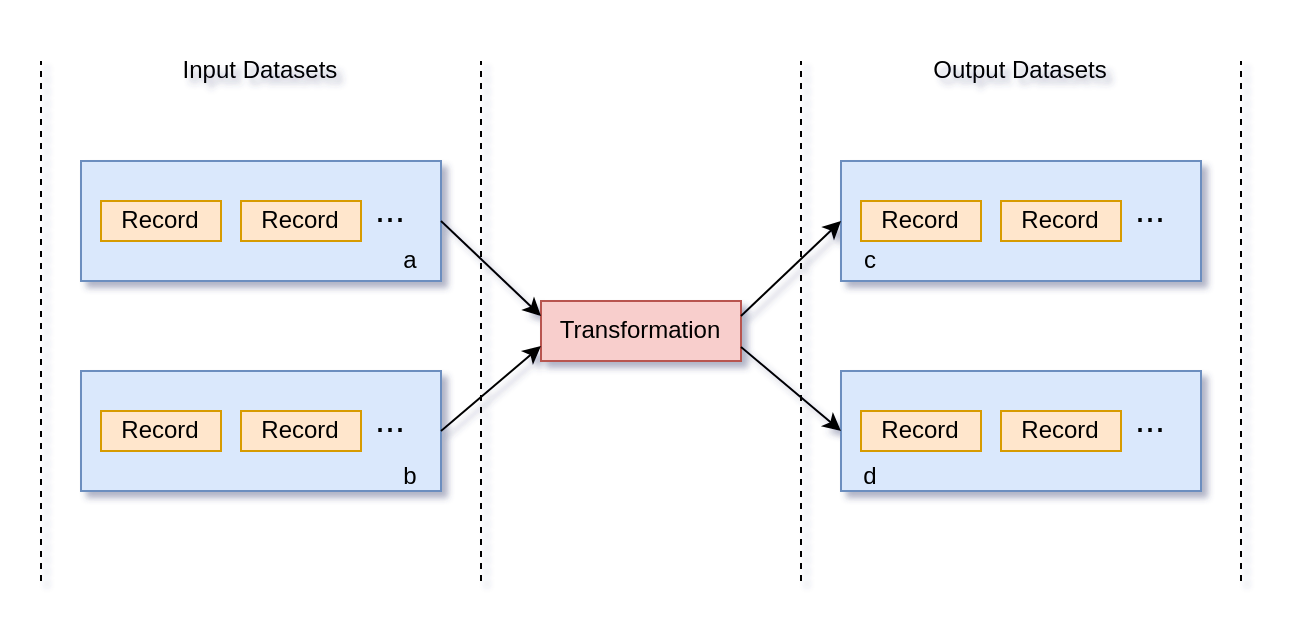
All processed records are routed to output datasets c and d. However, we
can control which record goes where using a conditional routing. There are two
ways to specify conditional route:
output_datasets:
- <dataset-name>: <condition>
or
output_datasets:
- name: <dataset>
condition: <condition>
For each record, the condition will be evaluated for all output datasets and routed to those where the condition is met. If condition is not specified, it will be always routed.
Ignore Errors
Ignore errors logic allows you to safely handle errors that happened during processing. These errors are expected and can be disregarded. There are two kinds of ignore errors:
- Returns unprocessed record - Error that happened means that we cannot process a record and we just return input record
- Returns processed record - Error that happened was ignored and we can continue with transforming the record. For example, if output field already exists in the record, this should throw an error say that transformation cannot output its value since the field is already there. Ignoring it would be that we can safely overwrite the field, which returns a processed record
Ignore errors can be specified for all transformations
...
transformations:
- transformation:
...
ignore_errors:
- output_already_exists
- field_wrong_type
- custom_exception
...
...
...
If error happens but the error is not ignored, it will be routed to
failed records. Additionally if instant_fail is enable, it will fail the
whole flow immediately.
Besides creating custom transformation, users can also add custom exceptions, for more information on that, please see Custom Exception.
Configuration
Flow Configuration
Flow configuration is defined using YAML files. This configuration is then
parsed in FlowConfigurationLoader instance and an instance of
FlowConfiguration is created. FlowSchema defines the schema of flow
configuration and what kinds of parameters we can use, for example
description- Description of the flowpath_separator- Sets field path separator for all transformations in the flow. This path separator will be used to access nested record fields.instant_fail- Stops the whole flow if a single transformation failstransformations- List of transformations that will be applied on each recordvariables- Defines flow level variables that can be used in any transformation during the processingfail_scenarios- Defines in which scenarios we want to fail the flow after processing. For example, when the percentage of failed records is above some threshold.parallel- If enabled, the flow execution will be done using multiprocessing, each process will run its own pipeline, and the data will be joined at the end to produce as single dataset result. Defaults to False, i.e. single processcores- Number of cores which will be used to execute a Flow in multiprocessing modebatch- Batch size i.e. number of records that will be processed in a single process when the multiprocessing mode is enabled
and many more, check pytransflow.core.flow.schema.FlowSchema for more
information.
Let’s use the following flow configuration for illustration purposes
parallel: True
batch: 2
cores: 2
path_separator: ","
fail_scenarios:
percentage_of_failed_records: 50
number_of_failed_records: 4
datasets_present:
- l
datasets_not_present:
- x
variables:
a: B
transformations:
- add_field:
name: a
value: b
- prefix:
field: a
output: a
value: test
condition: "@b,c == !:a"
ignore_errors:
- output_already_exists
output_datasets:
- k
- add_field:
name: test/a/b
value: { "a": "b" }
input_datasets:
- k
output_datasets:
- x
- z
If you run this flow with input record {"b": {"c": "B"}}, you’ll get the
following dataset
{'x': [{'b': {'c': 'B'}, 'a': 'testb', 'test/a/b': {'a': 'b'}}],
'z': [{'b': {'c': 'B'}, 'a': 'testb', 'test/a/b': {'a': 'b'}}]}
If you are not sure how to run this flow, please see Getting Started for more information and guidance on how to run pytransflow
Transformation Configuration
If you check FlowSchema, you’ll see that transformations parameter is
defined as transformations: List[Dict[str, Any]]. Meaning, flow configuration
is not imposing any configuration for transformations. However, during the
initialization of FlowConfiguration, this list of dictionaries will be
resolved to actual Transformation classes using the key which corresponds to
transformation name in TransformationCatalogue.
TransformationCatalogue is a mapping of <transformation-name> to its
Transformation and TransformationSchema classes. TransformationSchema is
used for configuration validation, while Transformation defines actual
transformation logic implementation. In other words, while parsing and
instantiating FlowConfiguration, each dictionary in transformations
parameter will be fetched from TransformationCatalogue and validated based
on key value i.e. <transformation-name>.
This logic allows users to define custom transformations by adding new
entries to TransformationCatalogue before instantiating a Flow. For more
details, please see Custom-Transformations.
All transformation schemas inherit from TransformationSchema, which has the
following parameters
input_datasets- Since transformations can have records from multiple input datasets. This arguments specifies the list of input datasets which records will be processed.output_datasets- List of output datasets where the processed records will be routedignore_errors- List of ignore failures that will be ignored if transformation encounters them during the processingcondition- Defines a condition for applying a transformation. If condition is met the transformation will be applied, otherwise it will be skippedrequired_in_record- This parameter is used to specify the fields that are required in the record. These fields are then checked by the Analyzer before the transformation is applied. Users should never set this parameter explicitly, it will be set dynamically based on transformation schema.output_fields- This parameter is used to specify the output fields. The presence of these fields will be checked by the Analyzer and theOutputAlreadyExistsExceptionwill be thrown if not ignored. Users should never specify this parameter explicitly, it will be set dynamically based on transformation schema.
This means that all transformations will have input_datasets,
output_datasets, ignore_errors, and condition parameters by default.
Allowing users to deal only with implementation logic.
Let’s use PostfixTransformationSchema for illustration purposes
from typing import Optional
from typing_extensions import Self
from pydantic import Field, model_validator
from pytransflow.core.transformation import TransformationSchema
class PostfixTransformationSchema(TransformationSchema):
"""Implements Postfix Transformation Schema"""
field: str = Field(
title="Input Field",
description="Input field where the data to be processed is stored",
json_schema_extra={"required_in_record": True},
)
value: str = Field(
title="Value",
description="Defines prefix value",
)
keep_original: bool = Field(
default=False,
title="Keep Original",
description="If True the original field will be kept, otherwise it will be deleted",
)
output: Optional[str] = Field(
default=None,
title="Output field",
description="Output field where the processed data will be stored",
json_schema_extra={"output_field": True},
)
@model_validator(mode="after")
def configure(self) -> Self:
"""Configures Postfix Transformation Schema"""
if self.output is None:
self.output = self.field
self.ignore_errors.append("output_already_exists")
self.set_dynamic_fields()
return self
Besides adding new parameters to transformation schema like field, value,
keep_original, output, users can use model_validator(mode="after") to
fine tune the logic and dynamically set fields.
Additionally, json_schema_extra is used to specify output_field and
required_in_record for certain fields. This is later used in Analyzer before
the transformation is executed. For example, if field has
json_schema_extra={"required_in_record": True}, it’s value will be required
in the record before transformation is executed.
These functionalities come from pydantic, which pytransflow utilizes to enable straightforward usage and smooth integration with its operational logic.
Global Configuration
Global configuration parameters define variables that are used through
the pytransflow’s codebase. For example, $FLOWS_PATH defines where the
flows are stored, it can be either absolute path or relative.
All parameters have default values, which users can change using
pyproject.toml or .pytransflowrc.
During the loading of pytransflow library and initialization of Flow
object, pytransflow will trigger TransflowConfigurationLoader. This class
will search for pyproject.toml or .pytransflowrc and load the configuration
if it’s present. pyproject.toml has precedence over .pytransflowrc.
Once the configuration files are loaded, it will create
TransflowConfiguration singleton, which is used through the code.
Check Global Configuration page for more information about the parameters and how to set them.
Flow
Instant Fail
If we don’t want to deal with failed records we can enable instant fail logic
...
instant_fail: True
...
transformations:
...
Enabling it will cause the flow to fail immediately when a single failed record is recorded. This is useful when don’t expect errors or failed records in a pipeline. Since it fails immediately, it will stop further unnecessary processing and notify errors straight away.
Flow Variables
Flows can have variables which are available to all transformation in a flow. They can be set in a flow configuration
...
flow_variables:
a: B
...
transformations:
...
or directly from a transformation’s transform method.
self.variables.delete_variable()
self.variables.get_variable()
self.variables.set_variable()
self.variables.update_variable()
Note: This should be used with caution, especially when parallelization is enabled, since it can introduce unexpected results.
These variables can be used in condition expressions using !: prefix
...
variables:
d: "A"
...
transformations:
- transformation:
...
condition: "@a == !:d"
Flow Fail Scenario
We can define scenarios when we want a flow to fail. These scenarios are related to the end state of processing. For example, we can define a scenario where we want to fail a flow if number of failed records is greater than some threshold.
These scenarios are evaluated against the end state and using FlowStatistics.
This class is meant to gather and process statistics related to a flow,
for example, percentage of failed records. Then we can easily create a
scenario where we don’t want to have a successful flow if % of failed records
is above some threshold.
For example
fail_scenarios:
percentage_of_failed_records: 50
transformations:
- add_field:
name: a
value: 1
For more information and available flow fail scenarios, please see Flow Fail Scenarios.
Schema Validation
Schemas should be defined under $SCHEMAS_PATH as python files. The schema
class should inherit from pydantic’s BaseModel. pytransflow leverages
pydantic’s advanced features for schema validation, which removes
unnecessary fields and converts data types to align with the schema definition.
If something fails, the record will not pass the validation and an exception
will be raised.
Schemas are loaded when a validation transformation is called
transformations:
- add_field:
name: a
value: b
- validate:
schema_name: test.TestSchema
schema_name is defined using <filename>.<class-name>.
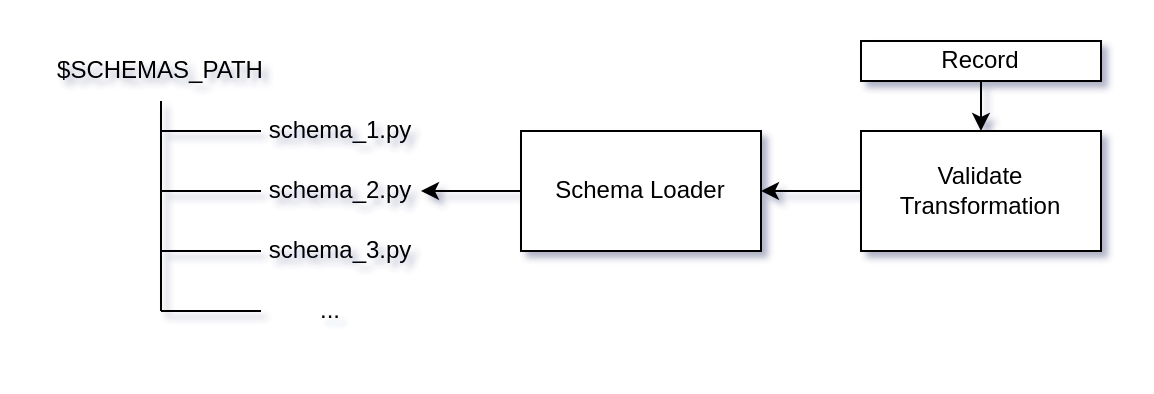
Parallelization
pytransflow can be run in parallel. Flow configuration takes the following parameters that will enable the parallelization
...
parallel: True
batch: 2
cores: 2
...
transformations:
- transformation:
...
...
batch and cores are optional. If not set, cores will default to
available cores on a machine using os.cpu_count(). Number of batches,
defines how many records we want to send to each core. If not defined,
it will default to len(input_records) / cores.
Each core will run its own FlowPipeline and process records from a single
batch, after gathering processed and failed records, we join results
from multiple pipelines and produce a single result Dataset.
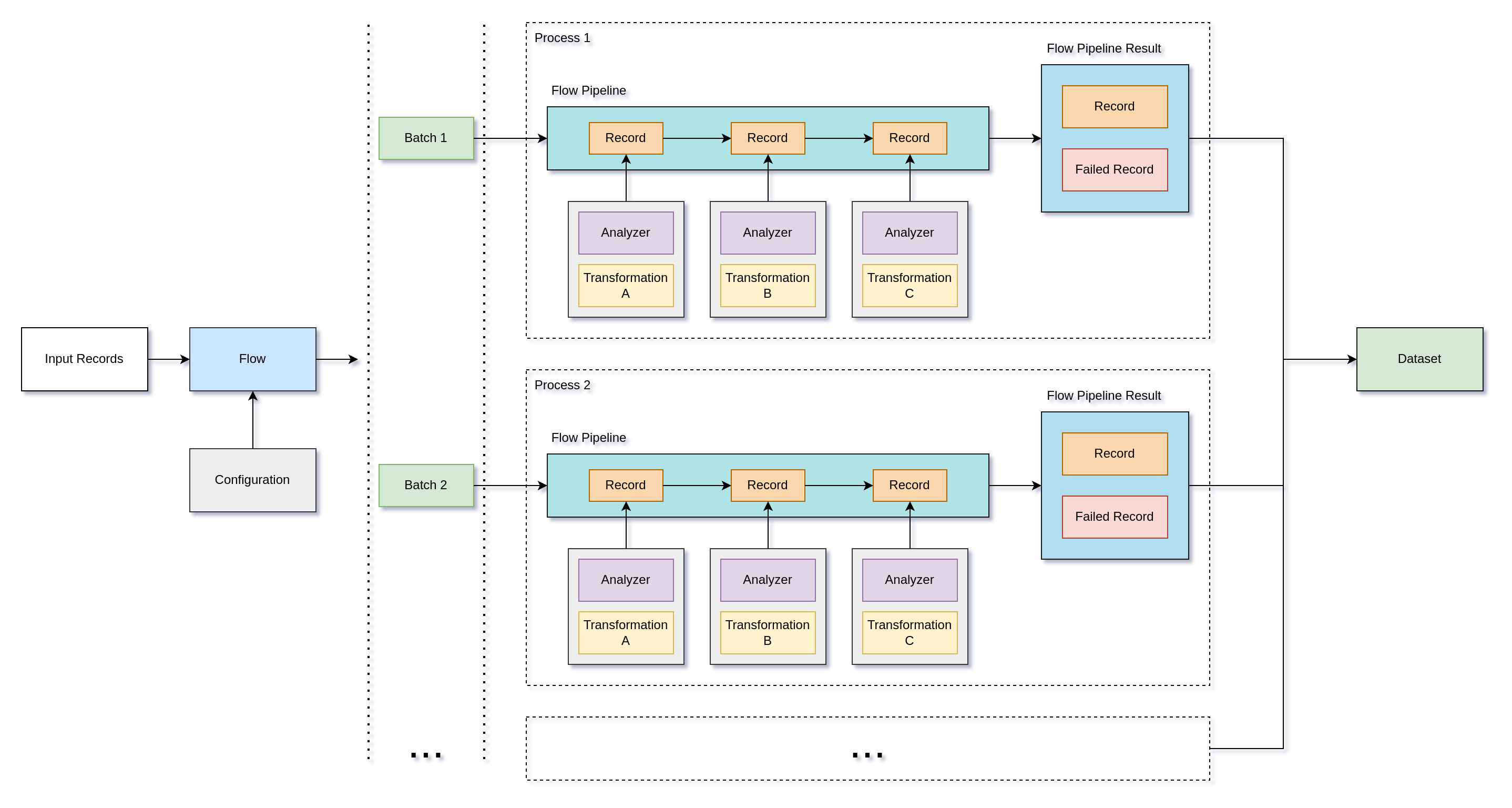
Global Configuration
pytransflow has several options that can be configured on a global level.
PATH_SEPARATOR- Configures a value that will be used for nested paths. Defaults to/. Flow configurationpath_separatorparameter will override it only for that flowSCHEMAS_PATH- Path of the folder where schemas are defined. Defaults to./schemas. Can be configured as relative or absolute path.FLOWS_PATH- Path of the folder where flows are defined. Defaults to./flows. Can be configured as relative or absolute path.DEFAULT_DATASET_NAME- Name of the initial default dataset. Defaults todefault.
Note: If
path_separatoris defined in a flow configuration file, it will override the global configuration for that flow only
You can use .pytransflowrc file in the root of the project or add the following
section to the pyproject.toml
.pytransflowrc
You can create .pytranflowrc file in the root of your project and define
global configurations that will be applied to the whole pytransflow library
[MASTER]
schemas_path = custom_schemas
flows_path = custom_flows
path_separator = ,
default_dataset_name = inital-dataset
pyproject.toml
For example:
[tool.pytransflow]
schemas_path = "/home/user/projects/test-pytransflow/custom_schemas"
flows_path= "/home/user/projects/test-pytransflow/custom_flows"
path_separator= ","
default_dataset_name="inital-dataset"
Custom Transformations
pytransflow comes with a plethora of predefined and highly customizable transformations, for example:
add_field- Adds a field to the recordvalidate- Validates and imposes a schema on a recordprefix- Adds a prefix to the field’s valuepostfix- Adds a postfix to the field’s valueregex_extract- Extracts a string using regex patternremove_fields- Removes one or multiple fields from the record- And many more…
However, you can also define your own transformations by following the
blueprint for creating transformations and including them in the
TransformationCatalogue.
TransformationCatalogue contains mappings of transformation names to their
definition class Transformation and transformation schema class
TransformationSchema.
To include a new transformation to the TransformationCatalogue, use
the following
from pytransflow.core import TransformationCatalogue
TransformationCatalogue.add_transformation(
transformation_name="<name>",
transformation=<Transformation>,
schema=<TransformationSchema>,
)
The <name> defines the name that will be used in the YAML configuration
files to identify the transformation. Transformation is the implementation
of the transformation, it has to implement transform method which operates
on a record. TransformationSchema is the schema configuration of the
transformation which will be used to parse the configuration from YAML files.
You can override built-in transformations by defining your own implementation
and registering them under the same name in the TransformationCatalogue.
Example
Let’s define a transformation that operates on a single field, capitalizing
all characters if it’s a string; otherwise, it will raise the
FieldWrongTypeException exception. Since this operation is the same as
upper() we will call it Upper.
Let’s define UpperSchema, it has two arguments:
field- Name of the field which contains the valueoutput- Name of the field where we want to store the transformed value. Ifoutputis not specified, overwrite thefield.
The UpperSchema has to inherit from TransformationSchema.
from typing import Optional
from typing_extensions import Self
from pydantic import Field, model_validator
from pytransflow.core import TransformationSchema
class UpperSchema(TransformationSchema):
"""Implements Upper Transformation Schema"""
field: str = Field(
title="Field",
description="Input field",
required_in_record=True,
)
output: Optional[str] = Field(
default=None,
title="Output field",
description="Output field where the processed data will be stored",
output_field=True,
)
@model_validator(mode="after")
def set_output(self) -> Self:
if self.output is None:
self.output = self.field
self.ignore_errors.append("output_already_exists")
self.set_dynamic_fields()
return self
Notes:
- If the field is required in the record, use
required_in_record=TrueinsideField. This will be used to check the existence of the field in a record before actual invocation of the transformation- If the field is output of the transformation, please use
output_field=True. This will be used to check if output field already exists in the record and if it should be overwritten- If the output is the same as input field, we should add
output_already_existsinignore_errors, otherwise the transformation will always throwOutputAlreadyExistsExceptionexception- Always call
self.set_dynamic_fields()at the end ofmodel_validator. This method parses fields and looks for additional arguments likerequired_in_record,output_field, etc, and sets required parameters.
The pydantic’s model_validator(mode="after") takes care of setting output if it’s
not defined. Likewise, you can use any other pydantic feature to manipulate
and define transformation schemas.
The actual transformation should take the original value, check its type, and
transform it if the value is str, otherwise throw FieldWrongTypeException
exception.
The Upper class has to inherit from pytransflow Transformation base class,
and implement transform method.
from pytransflow.core import Transformation, Record,
from pytransflow.exceptions import FieldWrongTypeException
class Upper(Transformation):
"""Implements Upper transformation logic
Upper Transformation transforms a record by applying `upper` function to a
specified field value and output is to defined `output` field
"""
def transform(
self,
record: Record,
) -> Record:
output_field = self.config.schema.output
field = self.config.schema.field
initial_value = record[field]
if not isinstance(initial_value, str):
raise FieldWrongTypeException(
field,
type(record[field]),
"str",
)
record[output_field] = initial_value.upper()
return record
Now, we can register this transformation in TransformationCatalogue
from pytransflow.core import TransformationCatalogue
TransformationCatalogue.add_transformation(
transformation_name="upper",
transformation=Upper,
schema=UpperSchema,
)
and use in a flow
transformations:
- add_field:
name: a
value: lower
- upper:
field: a
Running this flow with an empty record, we get
Result: {'default': [{'a': 'LOWER'}]}
Custom Exception
Besides creating a custom transformation, you can also create custom
exceptions that can be used in ignore_errors arguments.
Let’s say that you created a CustomTransformation transformation and you
want to raise CustomException if something goes wrong. All you have to do
is to inherit from TransformationBaseException and define name class
attribute in order for pytransflow to handle the exception with all the
features it provides.
from pytransflow.exceptions import TransformationBaseException
class CustomException(TransformationBaseException):
name = "custom_exception"
def __init__(self, error) -> None:
super().__init__(f"Error: {error}")
Here, we are defining name which can be used in flow configuration:
transformations:
- custom_transformation:
field: a
ignore_errors:
- custom_exception
Custom Evaluation
Evaluation of conditions in pytransflow is done using simpleeval library. This library allows us to extend the list of available evaluation functions.
Functions
For example, we can define our custom() function and use it in condition
expressions
from pytransflow.core import Flow, SimpleEval
def custom():
...
SimpleEval.add_function(
name="custom",
function=custom
)
records = [...]
flow = Flow(name="test")
flow.process(records)
and then use it in a transformation
transformations:
- add_field:
name: b
value: 1
condition: "custom(@a/b/c) == 'A'"
Note:
simpleevalcomes with a built-in set of functions, if you define the same function name, the built-in function will be overridden in runtime
Next Steps
It would be nice to extend pytransflow with the following features
Transformation Snippet
Transformation snippet would allow templating and parameterization of a group of transformations. For example, let’s say that we are performing the same group of transformations multiple times just on different fields:
transformations:
- add_field:
name: a
value: test
- prefix:
field: a
value: pre_
- postfix:
field: a
value: _post
- add_field:
name: b
value: test
- prefix:
field: b
value: pre_
- postfix:
field: b
value: _post
...
It would be nice to have a feature to define a transformation snippet
snippet:
name: snippet_example
transformations:
- add_field:
name: <field>
value: <val_1>
- prefix:
field: <field>
value: <val_2>
- postfix:
field: <field>
value: <val_3>
and the use it in a flow
transformations:
- snippet:
name: snippet_example
field: a
val_1: test
val_2: pre_
val_3: _post
- snippet:
name: snippet_example
field: b
val_1: test
val_2: pre_
val_3: _post
...
These snippets can be defined on a flow or project level:
- Flow - Use
snippetkey in flow configuration. If the snippet is defined on a flow level, it will be available only in that flow. - Project - Allow importing of snippets from a
SNIPPETS_PATHdirectory. These snippets will be available in all flows by default.
Custom Objects
Currently, pytransflow works only on dict records. Meaning, the input records
are defined and used in the following fashion
records = [{"a": 1}, {...}, {...}, ...]
flow = Flow(name="<flow>")
flow.process(records)
It would be nice to extend this and allow completely custom objects as input
records. This could be achieved by providing a custom class to pytransflow, and
replacing the default dict behavior. However, this custom class has to
implement required method in order to be used as Record.
For more information see
pytransflow.core.record.record.Recordclass
Ignore Errors on a Flow Level
A nice to have feature would be to define ignore_errors on a flow level.
These ignore errors will be applied to all transformation in the flow. This
would improve the readability and simplicity of flow configurations.
Instead of
transformations:
- add_field:
name: a
value: 1
ignore_errors:
- output_already_exists
- add_field:
name: b
value: 2
ignore_errors:
- output_already_exists
- add_field:
name: c
value: 3
ignore_errors:
- output_already_exists
...
Support
ignore_errors:
- output_already_exists
transformations:
- add_field:
name: a
value: 1
- add_field:
name: b
value: 2
- add_field:
name: c
value: 3
...
DAG
Because pytransflow defines a sequence of transformations that begin with an initial record and apply subsequent transformations sequentially, the underlying structure can be represented as Directed Acyclic Graph (DAG).
This feature would give users a nice graph representation of the flow, how transformations are connected and how datasets are routed between them. Having this feature would greatly improve the readability, documenting, and debugging of large and complex flows.
Parsing of the flow and defining graph structure should be done within pytransflow, while the visualization should be done using some external third-party library.
Debug Mode
pytransflow would significantly enhance its functionality with an extensive debugging mode that preserves the history of records. This mode would function in the same fashion as a data lineage within the workflow. Whenever a Failed Record or a successfully processed record occurs, users would be able to examine its complete history, tracing all transformations back to the original record.
Maintaining this history and enabling record traceability in case of errors would greatly improve the readability, testability, and maintenance of complex workflows. Moreover, leveraging DAG parsing, as previously mentioned, could further extend this history to generate clear graphs and comprehensive diagrams illustrating the transformation of each record through the processing pipeline.
Leave a comment