Exploring and Understanding Feature Stores

Introduction
Recently I’ve worked with multiple companies implementing MLOps. Most of the discussions revolved around automating and scaling ML projects effectively.
A common starting point in these conversations is: “We want multiple teams collaborating on ML projects, training models, and deploying them to production in a CI/CD fashion.” However, this approach often overlooks a critical question - how do you structure and scale model training in an organized and efficient way?
Many organizations rush to establish MLOps processes, allowing teams to move quickly but often leading to unmanageable infrastructure, duplicated efforts, and fragmented workflows. Without a well-defined foundation, scalability becomes a challenge rather than an advantage.
Given the complexity of MLOps, it’s crucial to break down its components. The better we understand each part of the ecosystem, the easier it becomes to design the right solution for a given use case.
One key component in this ecosystem is the Feature Store.
In this blog post, I’ll explore what a feature store is, why it’s essential, how it improves ML workflows, and the available options for implementing one in your projects.
Basics
Let’s remind ourselves of some basic concepts before focusing on the implementation details of feature stores.
When starting an ML project, the primary focus is on transforming raw data into meaningful inputs to build models that generate actionable insights. These insights drive smarter decision-making, enhance customer experiences, and boost business efficiency. While raw data contains diverse information and hidden patterns, only a subset of these patterns is relevant to solving the specific problem at hand. The variables that represent these critical patterns are known as features.
Features are individual measurable properties or characteristics used as inputs for a model to make predictions or classification. They are critical at the start of an ML project since selecting high-quality features ensures that the model captures the most relevant pattern in the data, reducing noise, and improving performance. Identifying the most relevant features for the target variable and discarding the irrelevant ones is called feature selection.
Turning the raw input data into a smaller set of features that capture the most important information in the data is called feature extraction. In some cases, datasets contain many highly correlated features, resulting in high-dimensional data that can lead to the curse of dimensionality. There are many types of dimensionality reduction techniques that can be applied to address this, such as Principal Component Analysis (PCA). The main idea behind these techniques is to transform the data into a set of uncorrelated principal components that capture the majority of the variance, effectively reducing dimensionality while preserving the most important information.
Using the domain knowledge, we can create new features from existing ones that are more informative and relevant for the target variable. The process of doing this is called feature engineering. For example, instead of using features \({x}\), \({y}\), and \({z}\), we decide to use \({e^{x} + \log(y)*z}\) instead, since our domain experts tell us that this derived quantity is more meaningful to solve our problem.
Once we have a set of features, we can think about them in terms of a feature space, which is a multidimensional representation where each feature i.e. variable corresponds to a dimension. In this space, data points are represented as vectors, allowing us to analyze patterns, measure relationships, and identify structures essential for building effective ML models.
Let’s say that we have features \(x_i\) where \(i=1,...,N\), giving us \(\mathbb{R}^N\) . Using feature engineering, we define additional two features \(f(x_i)\) and \(g(x_i)\). Then the feature mapping \(\phi\) is defined as \(\phi(x_i) = (x_i, f(x_i), g(x_i))\), which gives us \(\mathbb{R}^{N+2}\).
Feature Store
Now that we covered some basics, let’s focus on the feature store concept. Before diving into its details and internal structure, let’s first take a brief overview.
Underlying the aforementioned concepts, is the actual data and the processes that clean, transform, and prepare it for further use. Features are a structured representation of the data, requiring proper storage, monitoring, and quality assurance to ensure reliability. They must also be readily retrievable when needed by downstream processes, such as machine learning training or inference pipelines, to enable efficient and accurate model training and performance.
The main idea behind a feature store is to serve as a centralized repository that manages and serves features for ML processes. It streamlines the feature engineering process by enabling the consistent creation, storage, and retrieval of features while also ensuring data consistency across environments.
You can think of a feature store as a Git repository made for features. It includes tools for versioning, tracking feature metadata, and monitoring feature usage. However, feature store is more than a simple specialized repository for ML features, it’s an integral part of ML ecosystem that manages the entire lifecycle of feature engineering. Multiple teams can reuse the same features to train different models and easily discover feature datasets shared across the organization. A feature store acts as a centralized catalog, promoting collaboration and eliminating redundancy by providing a unified repository of features accessible to all teams.
Having all of this in mind, we can define 5 major components of a Feature Store:
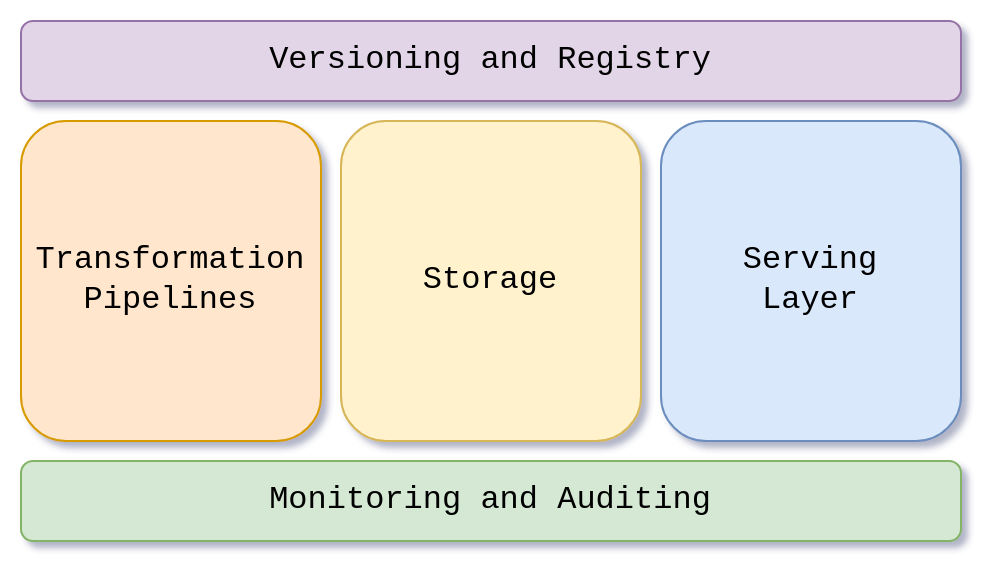
- Versioning and Registry - This component acts as a centralized repository for all feature groups and feature datasets in the feature store. It stores metadata such as raw data origin, transformations, format and how features are used in the pipelines, ensuring the consistency of feature definitions. Additionally, it controls versioning and access control
- Monitoring and Auditing - As with any other data system, monitoring is essential. Feature stores provide monitoring for data quality, data drift, serving performance etc. Depending on the feature store implementation, you can track and audit who accessed the feature datasets and when, enhancing security and ensuring compliance with regulatory requirements
- Transformation Pipelines - This component deals with processing data and storing it in the feature store. Transformations heavily depend on the use case and data source. In general, feature transformations should support automation and standardization of data pipelines that transform raw data into reusable features
- Storage - As the name implies, storing features for downstream use is the main goal of the feature store. This storage contains only precomputed feature values that are ingested via feature pipelines.
- Serving Layer - This layer allows other components of the ML system to interact with the feature store and retrieve features. Depending on the downstream process and required time frames, there are various methods to access the features.
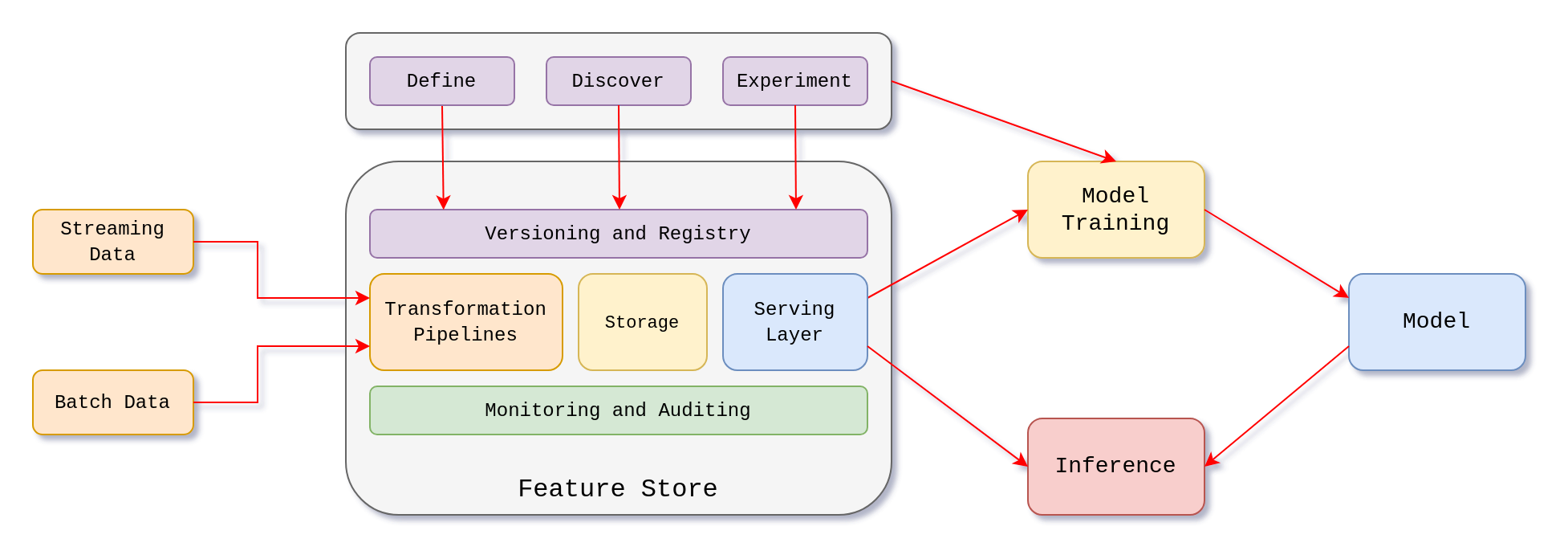
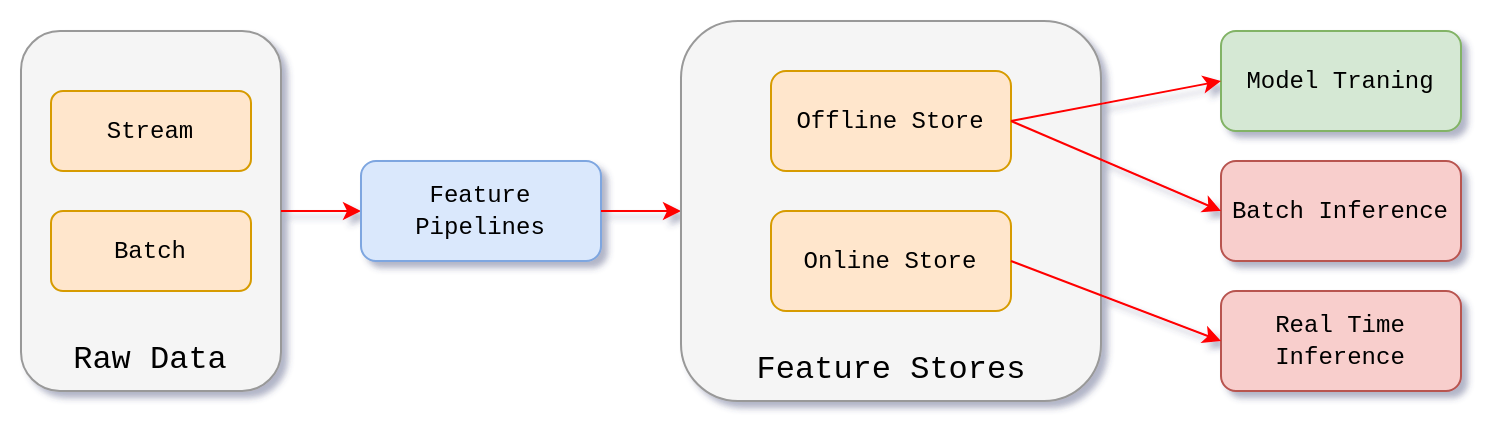
Looking at the broader picture of the MLOps, a feature store is a core component sitting between raw data pipelines and ML models. It serves as a bridge by transforming raw data into well-defined, reusable features that can be easily accessed for both training and inference. A simplified representation of a feature store within an MLOps infrastructure would look like this:
Benefits & Advantages
Let’s now focus on why we should implement a feature store in our MLOps infrastructure.
Centralized Feature Management
Imagine you’re working at a company that primarily uses data for traditional reporting purposes. You extract data from various third-party sources, load it into a landing zone, and organize it into bronze tables. From there, you transform and clean the data, eventually creating gold tables that power visualizations in a BI dashboard. At some point, you decide to enhance your dashboards with predictions by integrating machine learning models and serving inference endpoints.
Your existing data resides in data lakes, so you build additional ETL pipelines to generate features for the ML models. These pipelines process, transform, and store the features in separate data lakes. You then configure your training pipelines to pull data from these feature-specific lakes, using them as inputs for your models. This approach lays the groundwork for combining traditional BI reporting with predictive insights.
I’ve seen many companies follow this exact approach, and while it works well for experimenting or deploying one or two models, it inevitably leads to chaos as the organization scales and ML projects multiply. Simply processing data and storing it somewhere is not enough. You should also control access, manage feature lifecycles, monitor drift, provide tools for discovery and search, and ensure the quality and reliability of the data.
As the complexity grows - with teams creating diverse features, building numerous feature pipelines, introducing updates, and managing multiple feature versions across different projects - inefficiencies and inconsistencies become unavoidable. Without a structured system in place, you’ll quickly encounter significant challenges in managing and maintaining these features, hindering scalability and the success of your ML initiatives.
Feature stores allow you to easily scale and govern your ML project, it enables seamless collaboration between teams by serving as a unified repository for all ML features. This allows different teams to reuse pre-engineered features, eliminating redundant work and promoting consistency across projects. Among other things Features Stores provide lineage, version control, and automated updates. This means that if a feature requires an update due to new business logic or data changes, the updated version can be propagated across all dependent models with minimal effort.
In summary, it is an essential tool for any company looking to scale and optimize their ML operations.
Drawing a parallel with code management can help highlight the importance of a feature store. Do you technically need a Git repository to manage your organization’s code? No, you don’t. But can you imagine managing a team working on the same application without it? The chaos of version conflicts, lost changes, and inefficiencies would make collaboration nearly impossible.
Feature Consistency
There is another benefit of centralizing feature management and it’s quite important when it comes to guaranteeing the quality of predictions.
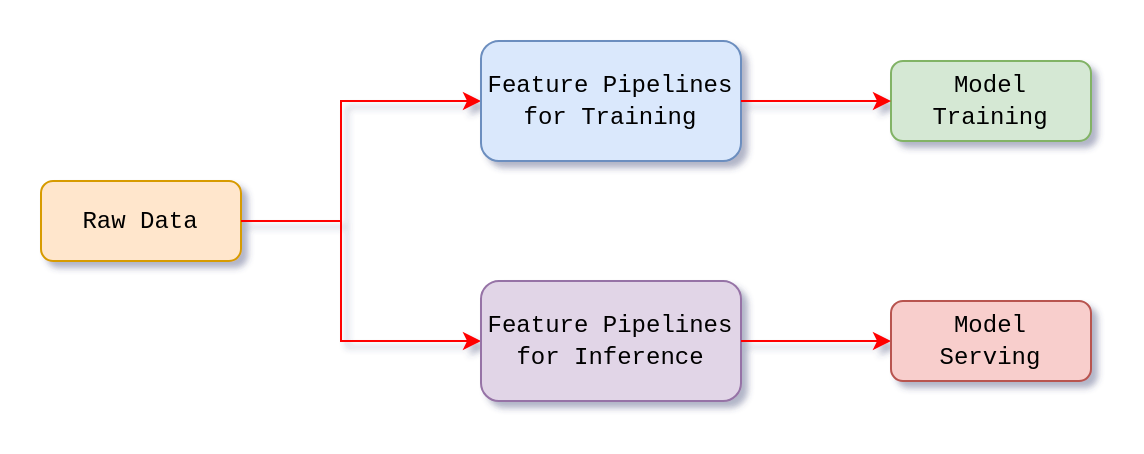
As we have seen, when you start implementing MLOps best practices, you will have different infrastructure for training and inference pipelines. Without a Feature store, teams face challenges such as duplicating logic for training and inference pipelines, especially for feature engineering, this can lead to increased risks of errors and inconsistencies due to data drift and mismatched transformations. This data drift, often referred to as training-serving skew , is difficult to detect and can significantly degrade model performance.
Training-serving skew is a difference between ML model outputs during the training and during serving. Basically, it is a discrepancy between an ML model’s feature engineering code during training and during deployment. Managing the same code and logic in multiple pipelines increases the model’s decay over time.
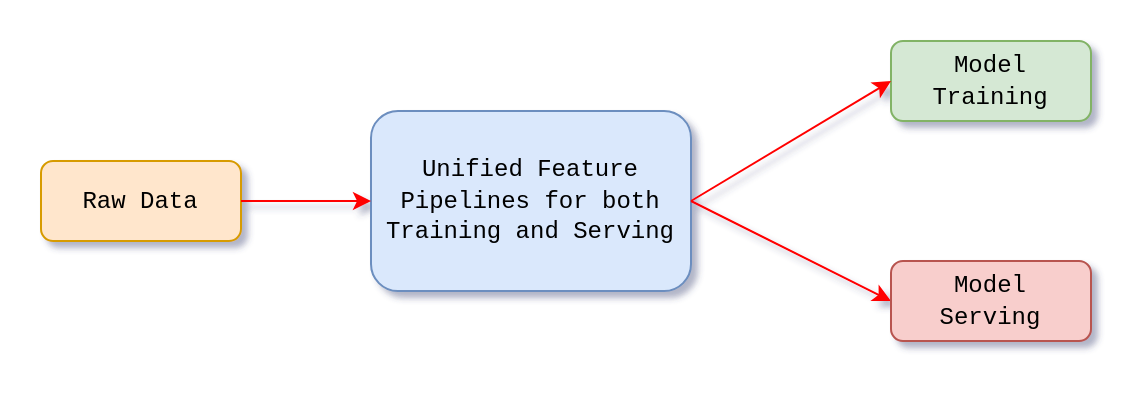
Using a feature store enables the creation of unified feature pipelines that serves both training and inference. It centralizes the feature definitions and metadata which ensures consistency in feature computation and management.
Batch and Real-Time Serving
Robust implementation of a feature store supports both batch and real-time feature serving. This is achieved by leveraging two kinds of storage types. It’s essentially a dual-database system, where feature store stores historical data in a columnar-oriented fashion and row-oriented retrieval system like relational database emphasizing quick, low-latency data lookup. We’ll take a closer look under the hood in the Internal Structure section. For now, let’s focus on the main takeaway points.
There are two types of stores.
Offline Store
Characteristics:
- Batch processing - Offline store is used for storing and processing large datasets. Its columnar-oriented storage makes it efficient to deal with transforming and querying large amount of data. It can be leveraged for both model training and batch inference
- High Latency - We should go for an Offline Store when we don’t have any time restrictions. For example when we want to make predictions for large datasets in batch fashion
- Historical Data - Since its storage is in Big Data format, we can efficiently store
- Version Control - Offline store can leverage Delta lakes, which provides with versioning for tracking changes, time traveling, and many other features
Online Store
History and Context for Online Models
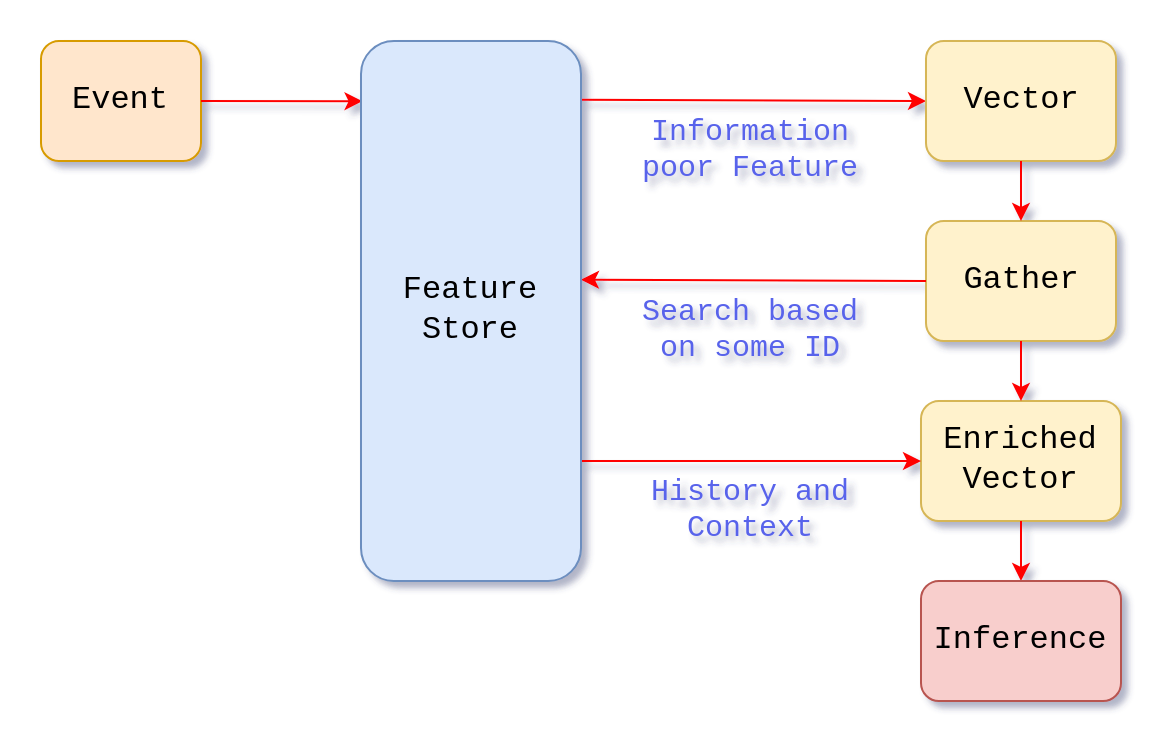
Suppose that we are building an application that tracks users across the platform and records the interactions i.e. click streams. We want to capture those interactions and build real-time prediction system using a trained model to make intelligent recommendations and capture users’ attention.
After training a model and deploying it in a model-serving infrastructure or a stateless application, we often need to make predictions based on user interactions, such as a click. However, a single click provides very limited information and lacks the context necessary for making accurate predictions about the user’s next action. The model is not aware of the history and context.
The solution to this problem is to use a feature store. Using the user’s ID we can retrieve precomputed feature from the online store containing the user’s personal history. On top of that, we can add trending context, such as popular and current content that can capture user’s attention.
In other words, feature stores enable applications and model serving infrastructure to take information-poor inputs and enrich them with features gathered from other parts of the Enterprise or external systems to build feature vectors capable of making better predictions.
Point-in-time Features
When we start dealing with time-series data and creating feature datasets, things can get tricky quite fast. One of the things we need to think about is data leakage. Data leakage is accidentally using data in model training that wouldn’t be available at the time of prediction or in other words, data leakage occurs when you use feature values for model training that were not available at the time the label was recorded.
Data leakage can be subtle and challenging to identify, yet its impact on business outcomes can be substantial. Models affected by leakage often exhibit unrealistically high performance during development but fail to deliver accurate results in production, where future data is unavailable.
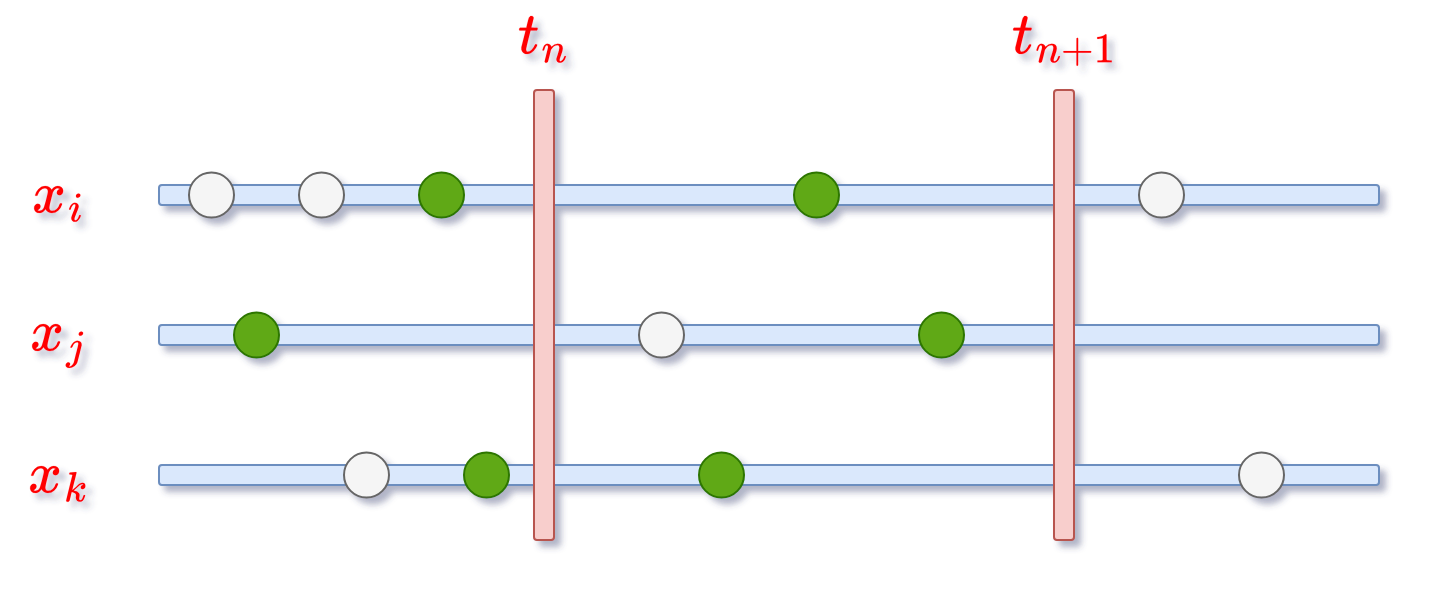
The illustration below shows three features \(x_{i}\), \(x_{j}\), and \(x_{k}\) on the time axis. At time \(t_{n}\) and \(t_{n+1}\) we record target variable. To build a valuable feature dataset and prevent data leakage, we should pick feature values recorded for each timestamp so that the value is the latest value before that timestamp, shown as green dots in the diagram. If the value is missing between two timestamps, the feature value should be null.
How can feature stores help here?
A robust feature store supports time-series feature tables with a dedicated timestamp key column. This ensures that each row in the training dataset reflects the most up-to-date feature values available as of that specific timestamp. Using this timestamp column, a feature store can perform efficient point-in-time correct queries.
The feature values are matched based on the primary key and the timestamp key using an AS OF join. This join ensures that the training set includes the most recent feature values available as of each specific timestamp.
If you are interested in learning more about point-in-time correctness, please check Databricks’ Point-in-time support using time series feature tables and AWS’ Build accurate ML training datasets using point-in-time queries with Amazon SageMaker Feature Store and Apache Spark articles.
Monitoring and Validation
In any machine learning system, monitoring is not just a nice-to-have - it’s necessary! The quality of your data directly impact the quality of your models and make the insights valuable. As the old saying goes: garbage in, garbage out.
Without proper monitoring, even the most sophisticated models can degrade over time due to data drift and skew, among other things, leading to poor insights and unreliable predictions.
When it comes to feature stores, staying ahead of data quality issues is critical as the feature store sits between raw data and model pipelines. This means we should continuously monitor for:
- Data drift - Detecting changes in data distribution over time, alerting you if significant changes occur. Common statistical methods for detecting data drift include Kolmogorov-Smirnov (KS) tests, Chi-Square tests, and Jensen-Shannon divergence, which compare the distributions of incoming and historical data
- Training-Serving Skew - As aforementioned, training-serving skew is a difference between ML model outputs during the training and during serving. This skew can significantly decrease the performance of our models
- Data Quality - Monitoring for data anomalies such as null percentages, date formats, or unexpected values etc.
- Serving performance - Whether you’re handling batch or real-time inference, monitoring the serving layer is critical. Key metrics such as throughput, serving latency, and requests per second provide valuable insights, allowing you to quickly identify and resolve bottlenecks as they arise
Internal Structure
At first glance, a feature store may seem like a black box filled with ready-made solutions and built-in features. However, a deeper look under the hood reveals a structured system with distinct layers that work together to build a powerful MLOps component, these layers can be roughly divided into:
- Data Infrastructure Layer - Takes care of ingesting, processing, and storing of data.
- Serving Layer - Gateway through which external applications can request and query features stored in the data layer.
- Application Layer - It serves as a critical layer for managing data pipelines, overseeing the feature lifecycle, and handling metadata. Additionally, it enables auditing and monitoring, ensuring seamless operation and governance of the entire feature store.
Of course, the structure of a feature store varies depending on its specific implementation. This breakdown is a simplified representation, intended for illustration purposes.
Let’s explore each of these layers in more detail.
Data Infrastructure Layer
The data infrastructure layer is the foundation of the feature store, responsible for managing data pipelines. Its primary role is to process data from both streaming and batch sources, build feature pipelines, and store features across different storage types, both online and offline.
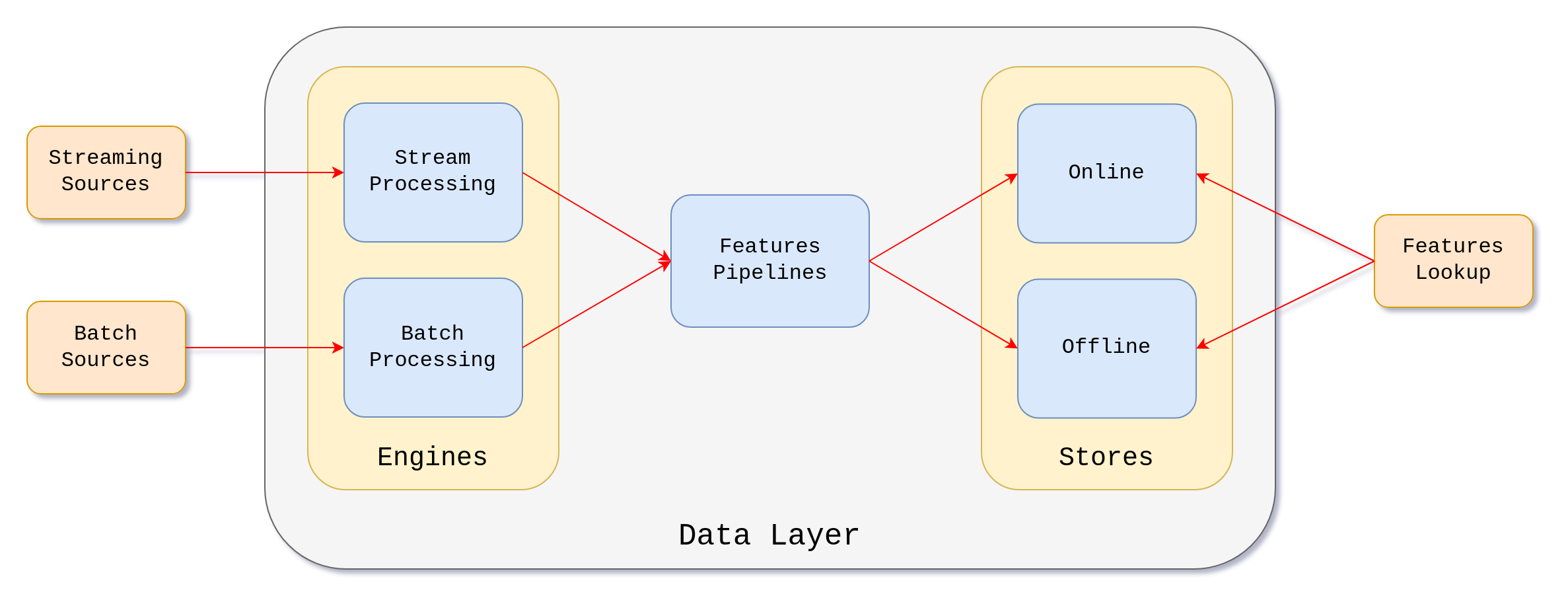
Cloud and data platform providers don’t build processing pipelines specifically for feature stores from scratch. Instead, most feature store implementations integrate existing processing engines with other compute services to handle data transformation and pipeline execution.
As an example, in Databricks space, we would use Jobs or Delta Live Tables pipelines in order to orchestrate data processing and storing. Similarly, in AWS we would leverage AWS Glue, AWS EMR, or AWS Kinesis Data Streams.
If we were to build a feature store from the ground up, we could utilize Apache Spark for both batch and stream processing, leveraging Structured Streaming for the latter.
Storage choices depend on the type of feature store. As we’ve seen, the offline store is designed for batch processing and historical data, where low-latency access isn’t a priority, but handling large volumes of data is. Given these requirements, object storage - such as an S3 bucket is a perfect fit.
On the other side, the online store requires fast and low-latency access to the data in order to provide with near-real time precomputed features for inference pipelines. Having this in mind, we could go with Redis. Its low-latency and high-throughput capabilities coupled with in-memory data structures provide fast read and write operations perfect for building real-time machine learning applications.
Later, in the History section, we’ll explore real-world feature
store implementations in more detail. However, it’s worth noting here that
AWS SageMaker Feature Store uses AWS ElastiCache for its InMemory online store,
leveraging a fully managed service compatible with Valkey, Memcached, and
Redis OSS. In contrast, Uber’s Michelangelo stores precomputed features for
online predictions in Cassandra. We’ll dive deeper into these implementations
later.
Serving Layer
The purpose of the serving layer is to act like an interface for external applications and services that request features, for example training and inference pipelines.
It should be designed for high availability, low latency, and high throughput, ensuring fast and reliable feature delivery. To enhance security, it must implement robust authentication and authorization mechanisms, along with rate limiting to prevent abuse and ensure fair usage. Additionally, it should track API usage, errors, and latency, enabling effective monitoring and performance optimization.
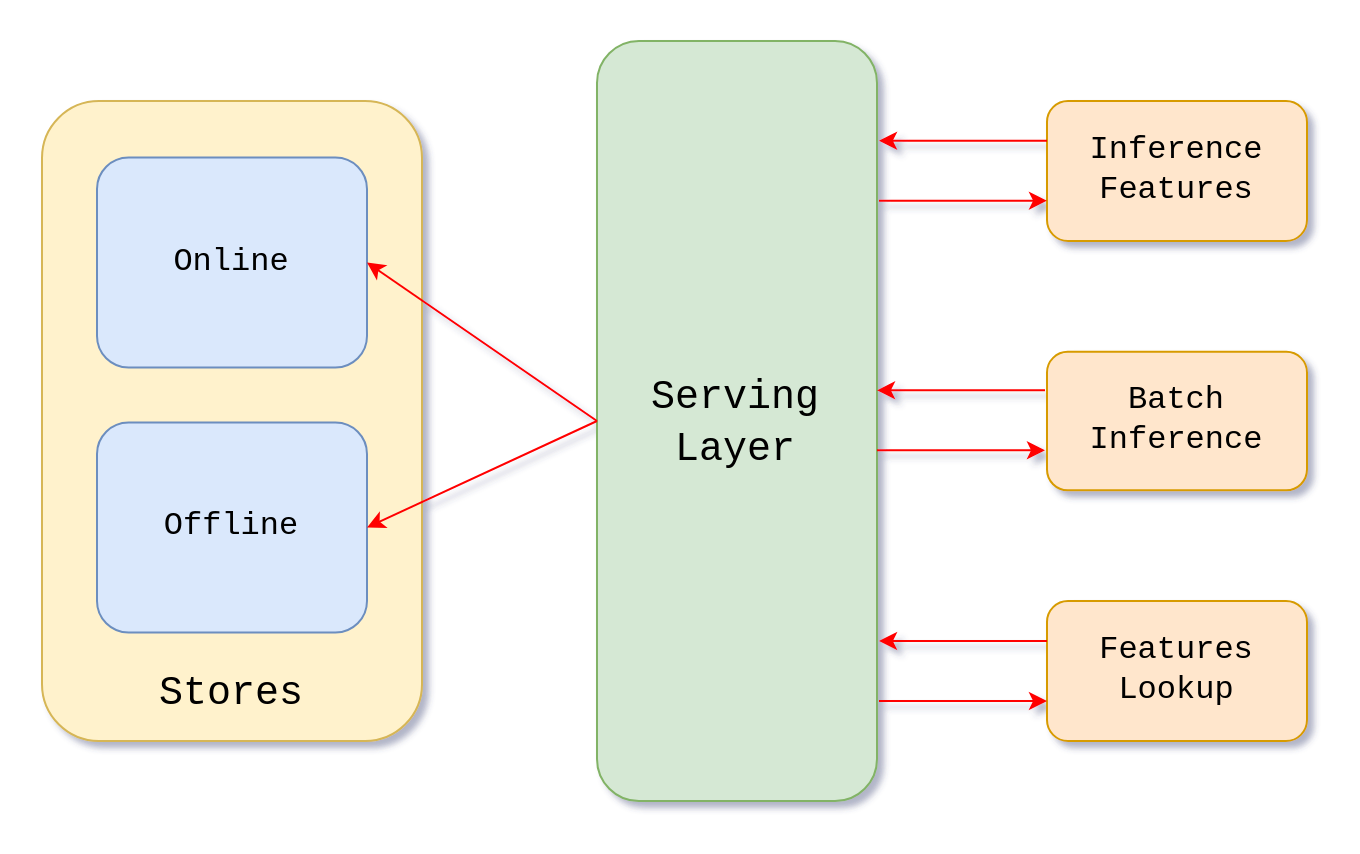
The specific implementation varies based on the feature store’s architecture and cloud provider. However, one best practice is to serve requests via a RESTful API behind a load balancer. Kubernetes is a good option, as it provides seamless scalability to meet these performance and reliability requirements.
Application Layer
The application layer serves as the control center of the feature store, managing data pipelines, tracking features and their metadata, collecting logs, and monitoring system health.
This layer can be further divided into several key components, including:
- Orchestrator - Coordinates ingestion pipelines and other feature store components.
- Feature Registry - Acts as a catalog of features, handling metadata, versioning, and lineage tracking.
- Logging and Monitoring Service - Captures system logs, tracks performance, and ensures real-time observability.
- Dashboard - A frontend application that provides a user interface for managing, reporting, and monitoring the system.
History
When exploring an architectural pattern, it’s valuable to step back and understand how we arrived at the current state. By following the progression of an idea, we can gain insights into how systems evolve and even anticipate what might come next.
As I researched for this blog post, I took the time to go back through different solutions and timelines that shaped the development of feature stores. I stumbled upon a good Medium article Feature Store Milestones detailing the early key advancements of feature store up to October 2021.
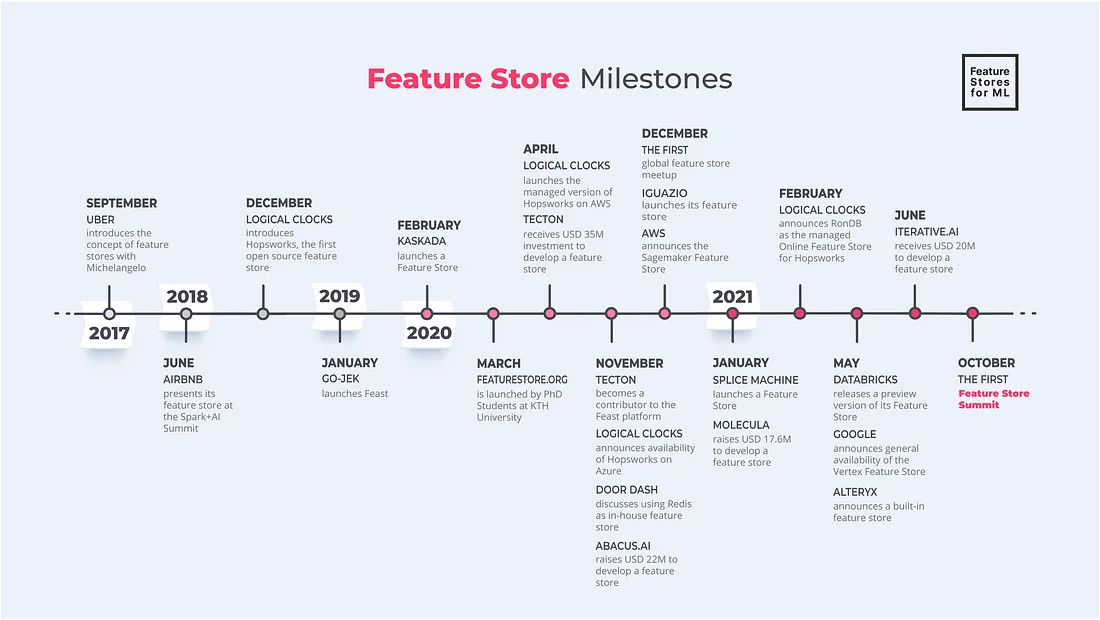
Between 2017 and 2021, feature stores established themselves as a fundamental component of the MLOps ecosystem, evolving from an emerging concept to a well-defined component in every organization that’s looking to scale its ML projects.
In this section, we will focus on some significant milestones in feature store development and highlight key contributions from industry leaders.
Uber - Michelangelo
Main article: Meet Michelangelo: Uber’s Machine Learning Platform.
In 2017 Uber developed Michelangelo, one of the first feature stores, to centralize feature engineering and serve features in production. Doing so, Uber introduced the concept of a feature store to the wider audience.
Michelangelo was designed to address gaps in the productivity, scalability, reliability of pipelines for creating and managing training and prediction data at scale. Feature store was just a component of the whole system.
Quote from the article:
When we began building Michelangelo in mid 2015, we started by addressing the challenges around scalable model training and deployment to production serving containers. Then, we focused on building better systems for managing and sharing feature pipelines. More recently, the focus shifted to developer productivity - how to speed up the path from idea to first production model and the fast iterations that follow.
High level overview of architecture behind Michelangelo
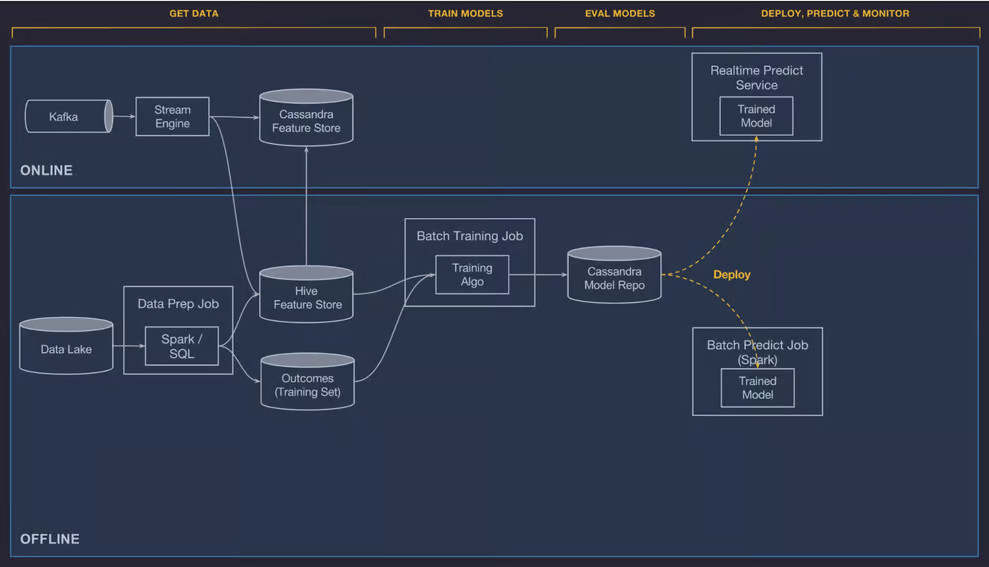
As we can see, the data layer is divided into online and offline pipelines. The offline layer is used for batch model training and batch prediction jobs, while the online feeds low latency predictions.
The offline data is stored into an HDFS data lake, which is then processed using Spark and Hive SQL compute jobs. The precomputed features for online predictions are stored in Cassandra.
The article goes into details regarding the architecture and how things are connected. Since we are focusing on the role of the feature store, it’s valuable to see how a shared feature store helped Uber scale their ML projects.
Quote from the article
We found great value in building a centralized feature store in which teams around Uber can create and manage canonical features to be used by their teams and shared with others. At a high level, it accomplishes two things:
- It allows users to easily add features they have built into a shared feature store, requiring only a small amount of extra metadata (owner, description, SLA, etc.) on top of what would be required for a feature generated for private, project-specific usage.
- Once features are in the feature store, they are very easy to consume, both online and offline, by referencing a feature’s simple canonical name in the model configuration. Equipped with this information, the system handles joining in the correct HDFS data sets for model training or batch prediction and fetching the right value from Cassandra for online predictions.
Google / GO-JEK - Feast
Main article: Introducing Feast: an open source feature store for machine learning.
In 2019, Google Cloud and GO-JEK announced the release of Feast, an open source feature store that allows teams to manage, store, and discover features allowing them to better scale ML projects.
Their motivation came from the fact that large teams introduce infrastructure complexity by maintaining features pipelines and serving endpoints across projects, which results in duplicated work.
They faced typical challenges, quoting the article:
- Features not being reused: Features representing the same business concepts are being redeveloped many times, when existing work from other teams could have been reused.
- Feature definitions vary: Teams define features differently and there is no easy access to the documentation of a feature.
- Hard to serve up to date features: Combining streaming and batch derived features, and making them available for serving, requires expertise that not all teams have. Ingesting and serving features derived from streaming data often requires specialized infrastructure. As such, teams are deterred from making use of real time data.
- Inconsistency between training and serving: Training requires access to historical data, whereas models that serve predictions need the latest values. Inconsistencies arise when data is siloed into many independent systems requiring separate tooling.
Their solution to these challenges was a system structured into three key layers: Ingestion, Storage, and Access, with a Core API serving as the application layer. This API facilitates feature store management, enabling seamless feature discovery and efficient querying for model pipelines.
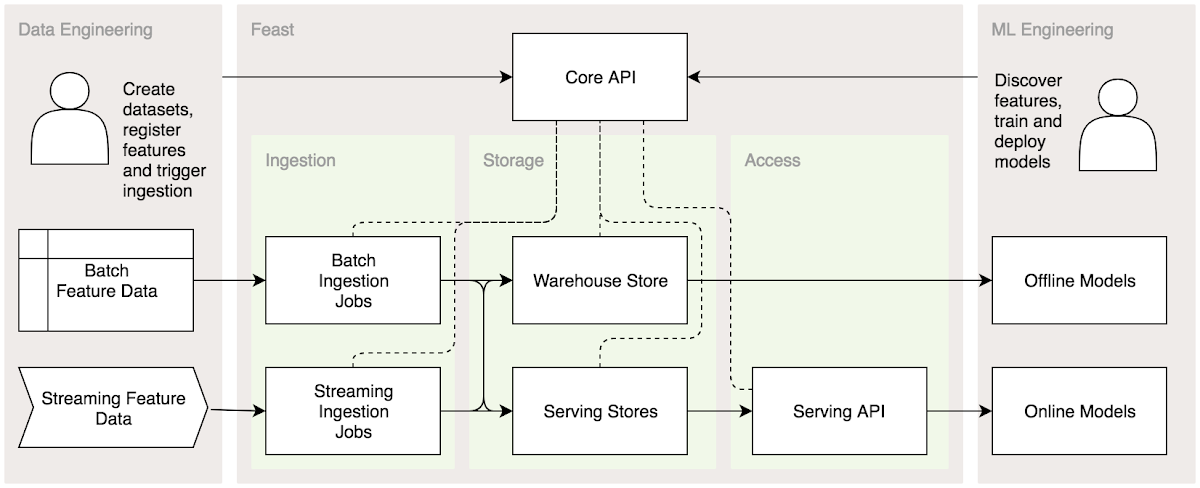
Feast enabled them to discover and reuse features, manage access to features for training and serving, while also keeping consistency between different pipelines standardizing the features.
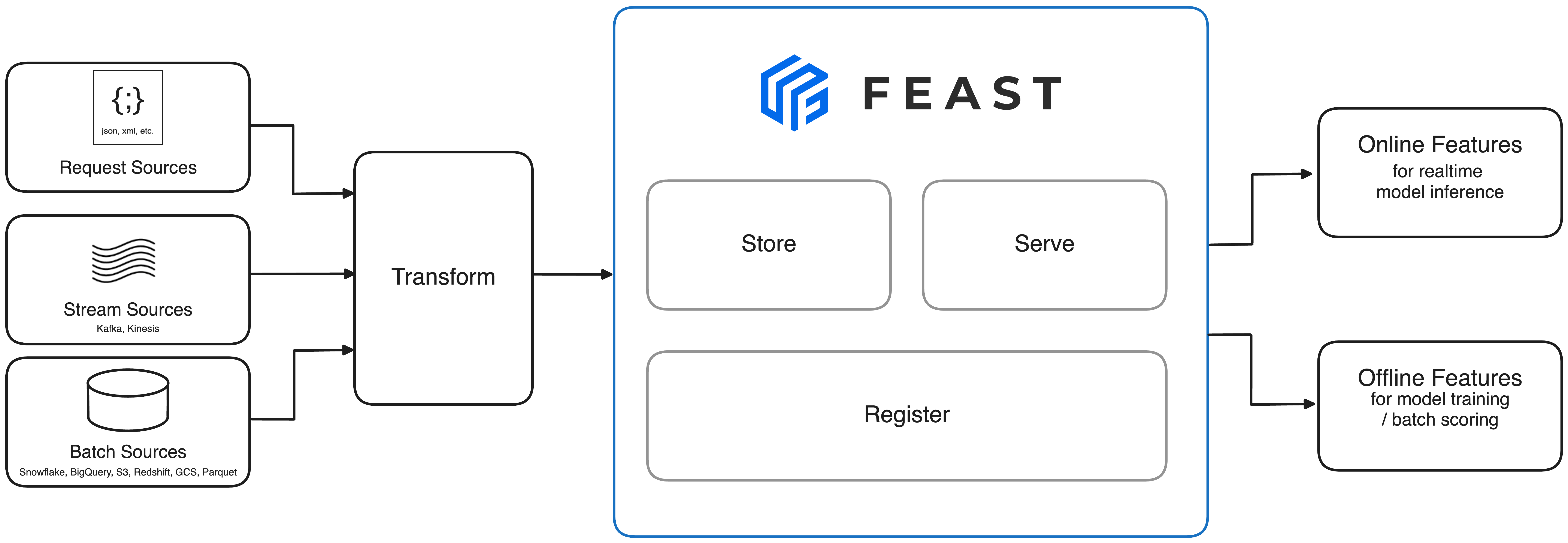
Feast is now a standalone, open-source project actively maintained by the community and easily integrable into your MLOps stack.. For more information, check the GitHub repo feast-dev/feast.
For more historical context, check this talk. The speaker is Williem Pienaar, one of the tech leads on a data science platform at GO-JEK, at the time.
Amazon Feature Store
Main Article: New - Store, Discover, and Share Machine Learning Features with Amazon SageMaker Feature Store.
In 2020, AWS announced Amazon SageMaker Feature Store, a new capability of Amazon SageMaker that enables data scientists and machine learning engineers to securely store, discover, and share curated data for seamless integration into training and prediction workflows.
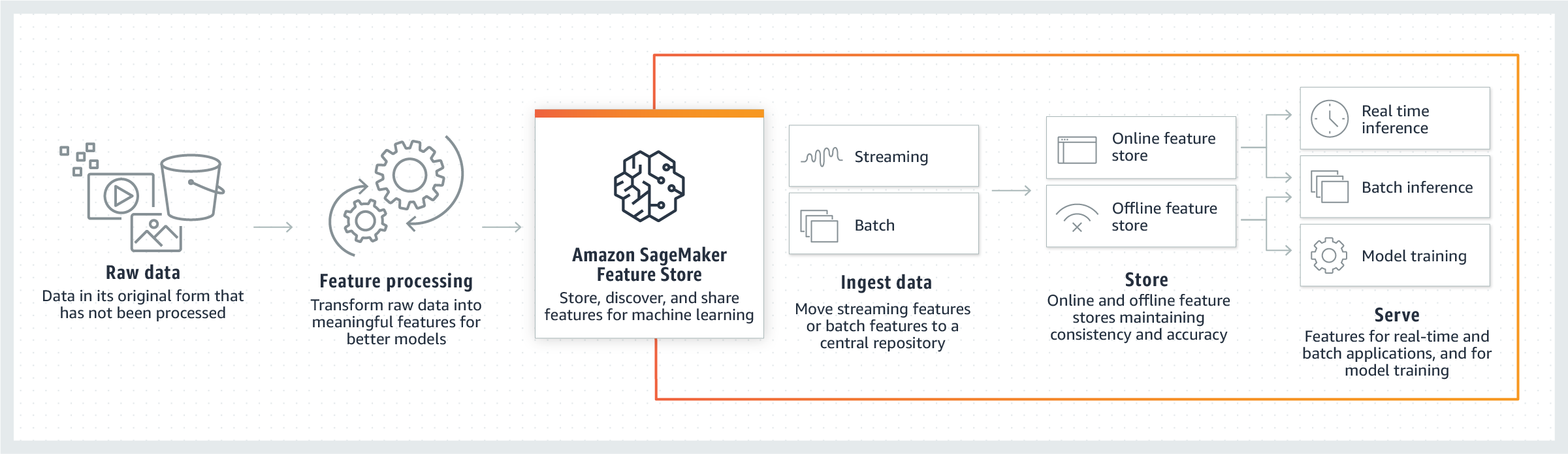
In contrast to Feast, AWS SageMaker Feature Store is fully managed centralized repository for ML features. There is no need to manage any underlying infrastructure. It fully integrates with Amazon SageMaker and Amazon SageMaker Studio, allowing teams to easily spin up an ML environment and develop pipelines.
Offline store is just an S3 bucket, allow you to use services such as Amazon
Athena, AWS Glue, or Amazon EMR to build datasets for training or batch
inference. Online store comes in two tiers, Standard and InMemory, which
leverages Amazon ElastiCache. For more information, please check AWS
documentation - Feature Store storage configurations.
Databricks Feature Store
Main article: Databricks Announces the First Feature Store Co-designed with a Data and MLOps Platform.
In 2021, Databricks announced the launch of Databricks Feature Store. First feature store co-designed and fully integrated with Delta Lake and MLflow.
Quoting the article
It inherits all of the benefits from Delta Lake, most importantly: data stored in an open format, built-in versioning and automated lineage tracking to facilitate feature discovery.
By packaging up feature information with the MLflow model format, it provides lineage information from features to models, which facilitates end-to-end governance and model retraining when data changes. At model deployment, the models look up features from the feature store directly, significantly simplifying the process of deploying new models and features.
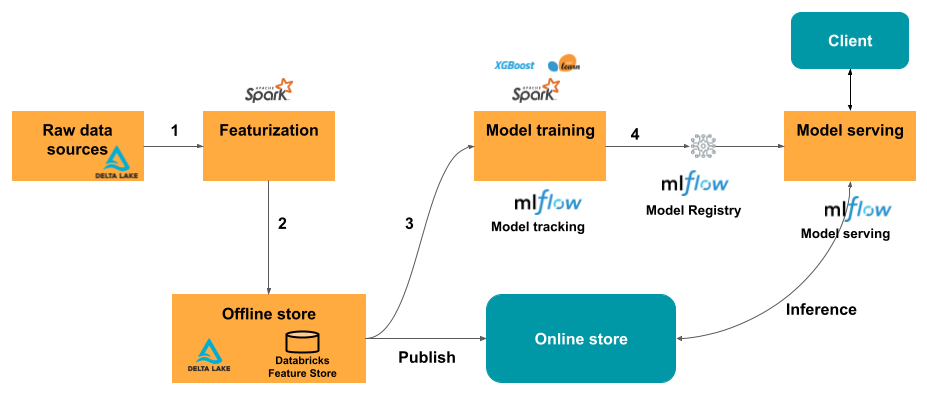
Beyond addressing common challenges in feature pipelines, management, auditing, and serving, Databricks’ Feature Store offers additional capabilities, including:
- Eliminating online/offline skew with native model packaging - When an MLflow model trained on feature store data is deployed, it automatically retrieves features from the appropriate online store, ensuring consistency between training and inference.
- Enhancing reusability and discoverability with automated lineage tracking - Integration with the MLflow model format enables full lineage tracking, mapping features to models and endpoints. This allows for end-to-end traceability and informed decision-making on feature table updates or deletions.
If you’d like to learn more, check out an excellent video from the Data + AI Summit 2021, where Databricks announced its feature store and explored its details in depth.
LinkedIn - Feathr
Main article: Open sourcing Feathr - LinkedIn’s feature store for productive machine learning.
In 2022, LinkedIn open sourced Feathr, the feature store built to simplify machine learning feature management and improve developer productivity.
As LinkedIn explains it in the article, they had usual challenges with scaling the ML operations across different teams, quoting the article
The cost of building and maintaining feature pipelines was borne redundantly across many teams, since each team tended to have their own pipeline. And pipeline complexity tended to increase as new features and capabilities were added over time. Team-specific pipelines also made it impractical to reuse features across projects. Without a common abstraction for features, we had no uniform way to name features across models, no uniform type system for features, and no uniform way to deploy and serve features in production. Custom pipeline architectures made it prohibitively difficult to share work.
To address these challenges, they developed Feathr, introducing an abstraction for two key personas: producers and consumers of features. Producers define and register features within Feathr, while consumers seamlessly access and import feature groups into their ML model workflows.
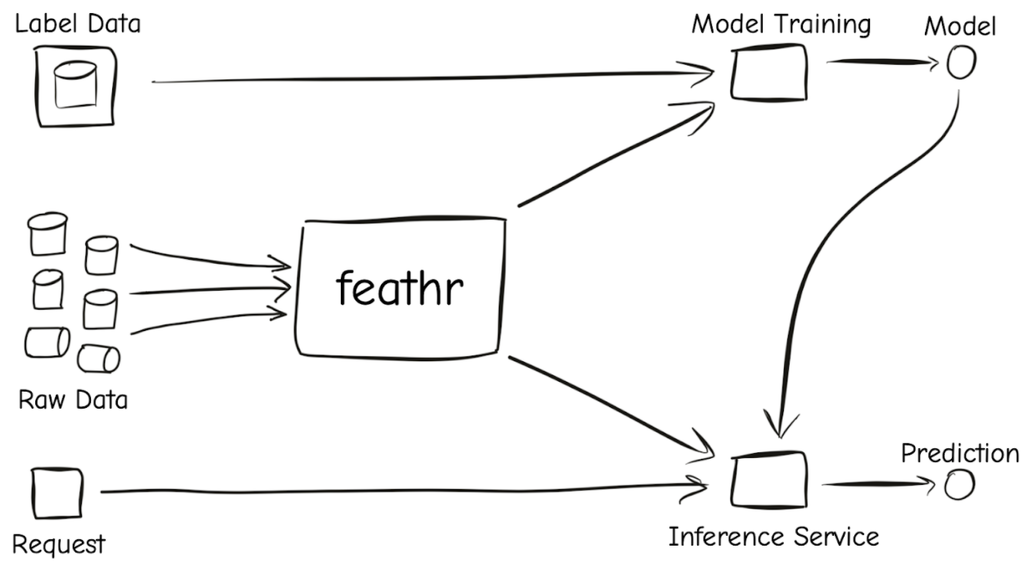
Feathr empowers you to:
- Define data and feature transformations from raw batch or streaming data sources using intuitive Pythonic APIs
- Register transformations by name and retrieve processed features for various use cases
- Share feature transformations and data seamlessly across teams and the entire organization
For more information check GitHub repo feathr-ai/feathr and YouTube video Feathr Feature Store Introduction.
Leave a comment